When Doshi and Vaishnav published their controlled experiment on AI code completion in Science (2023), the headline that propagated everywhere was "55.8% faster." Repeat it enough and it becomes received wisdom.
The actual paper measured time-to-completion on a single well-defined HTTP server task. A problem with a known shape, a stable target, and a scoring function that rewarded a specific solution path. The 55.8% lift was real for that task. It is also the narrowest possible reading of what "AI productivity" means in software work.
A more careful follow-up at HICSS-59 (Stray et al., 2026) looked at sustained workflow integration over weeks instead of a single benchmarked task. Numbers compressed. Across mixed work (greenfield, debugging, refactoring, code review) aggregate time savings landed closer to 10-20%, with high variance across task class. Debugging and code review barely moved. Greenfield CRUD work moved the most.
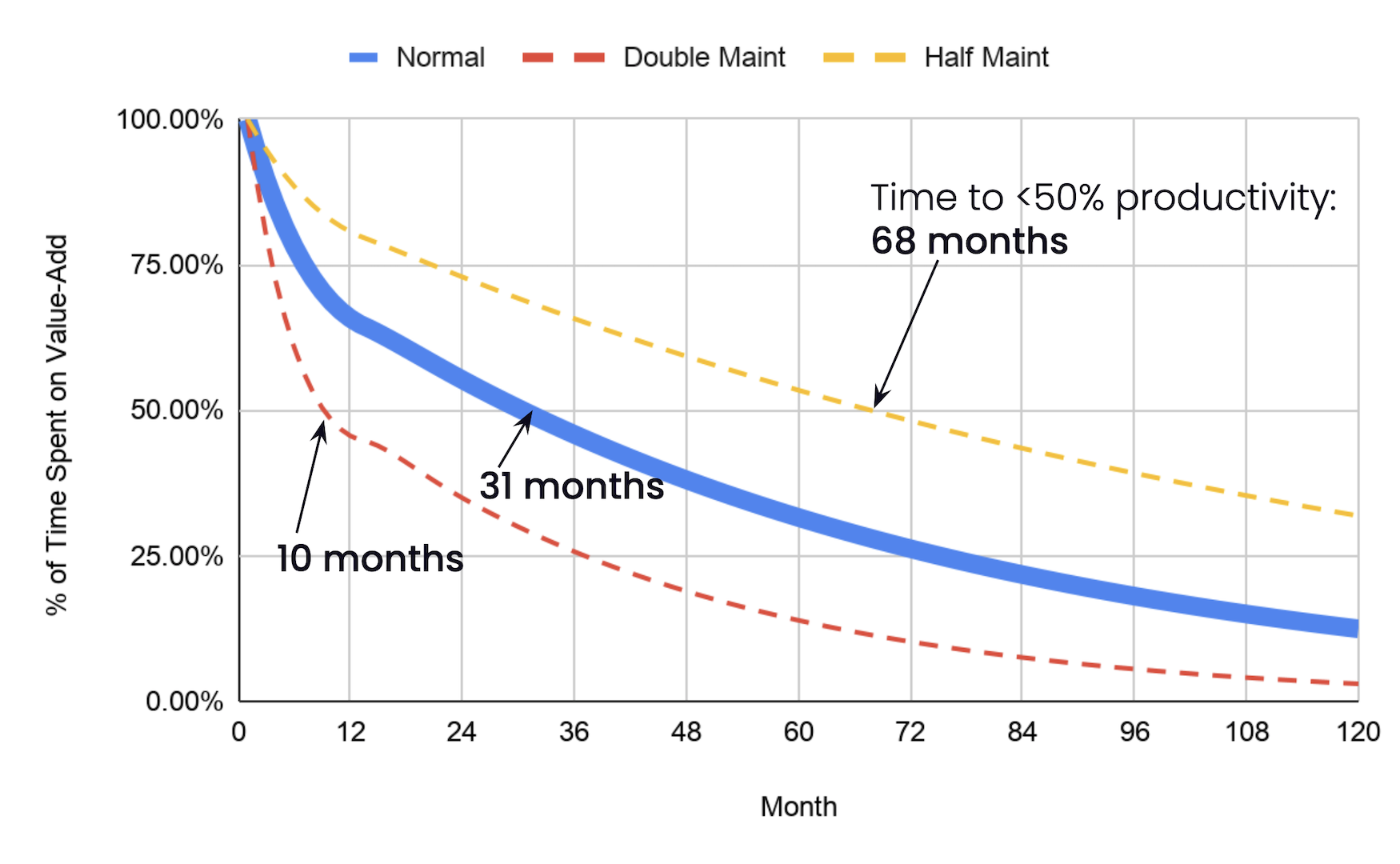
That gap between single-task lab benchmark and integrated weekly workflow is where most engineering org AI productivity decisions are silently going wrong.
The mechanism gap