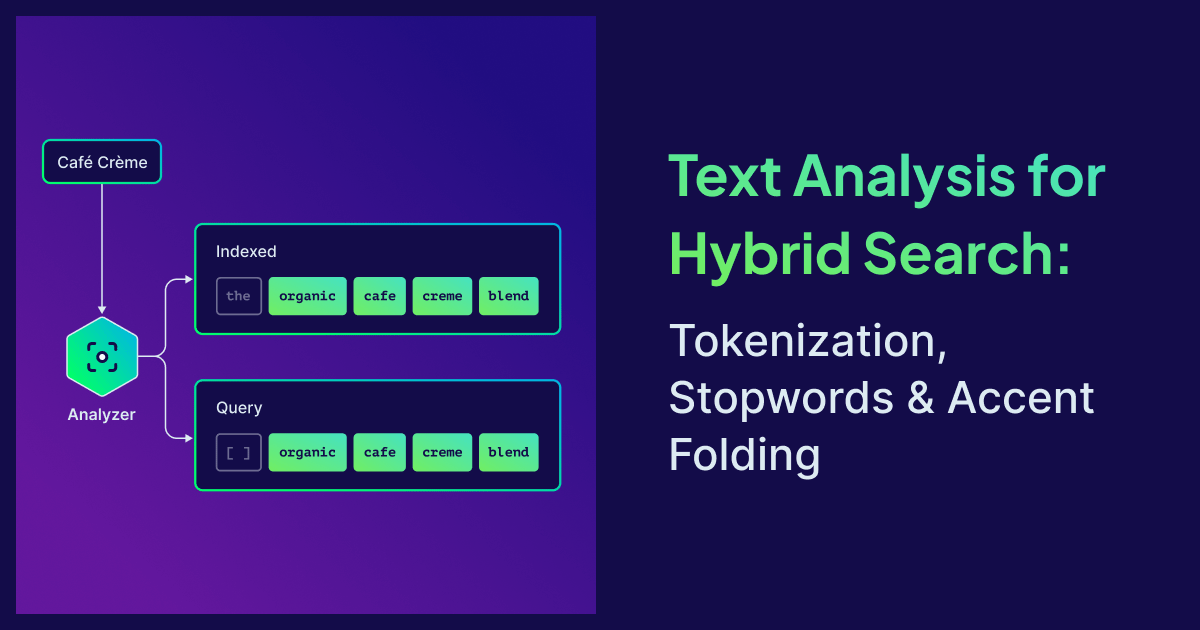
Hybrid search in a vector database has two halves: vector similarity for meaning, BM25 for exact tokens. The vector half gets all the attention. The BM25 half, and the tokenization that feeds it, quietly fails when the analyzer is wrong, and no amount of embedding tuning will save you. Drop the wrong character, split a word that shouldn't be split, and BM25 has nothing useful to match. The keyword side becomes noise and drags the search quality down with it.
That sounds like an edge case until you ship a multilingual catalog. Suddenly "café crème" returns nothing for a French e-commerce store, the Polish team can't find "Łódź", and your support agent's RAG pipeline misses every query that uses an accented word. The tokenizer was right there the whole time. Nobody could see what it was doing.
Weaviate v1.37 made the tokenizer an observable and multilingual-friendly part of the database. This post will help improve your search quality and covers the following topics:
Hybrid search 101 - How tokenization shapes recall in hybrid search
Tokenization methods - Picking the right tokenizer for your data