AI-native services are exposing a new bottleneck in AI infrastructure: As millions of users, agents, and devices demand access to intelligence, the challenge is shifting from peak training throughput to delivering deterministic inference at scale—predictable latency, jitter, and sustainable token economics.
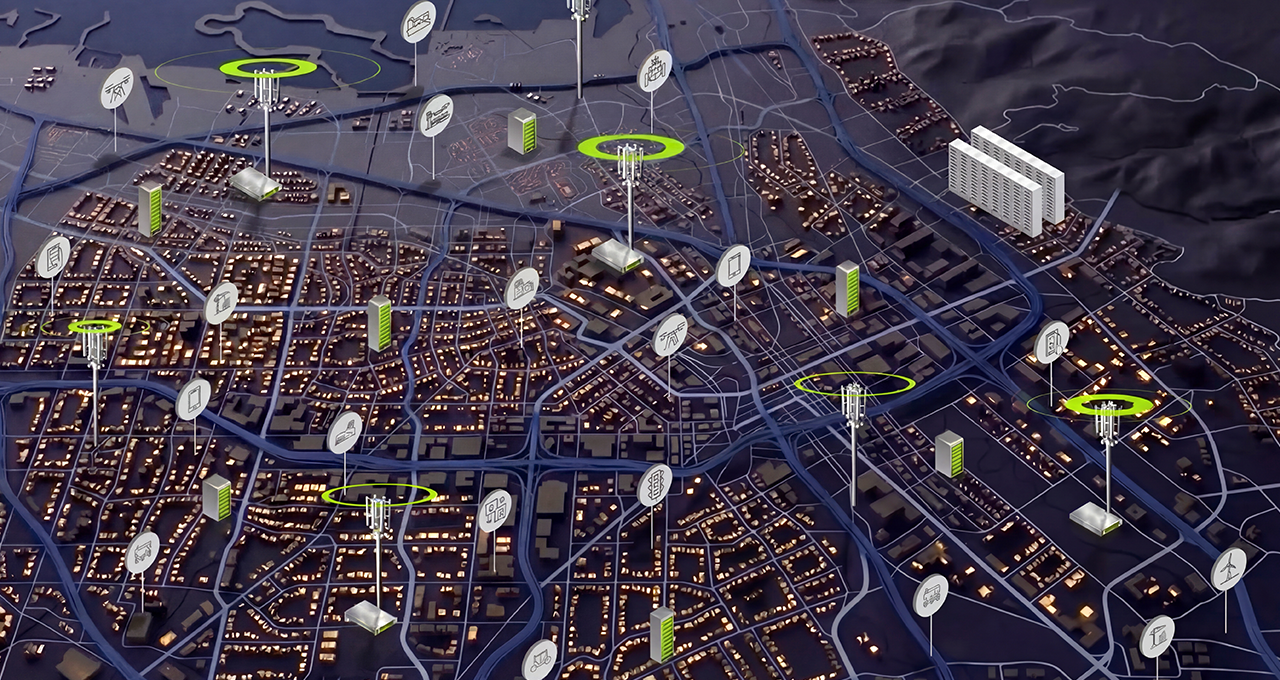
NVIDIA announced at GTC 2026 that telcos and distributed cloud providers are transforming their networks into AI grids, embedding accelerated computing across a mesh of regional POPs, central offices, metro hubs, and edge locations to meet the needs of AI-native services.
This post explains how AI grids make real-time, multi-modal, and hyper-personalized AI experiences viable at scale by running inference across distributed, workload-, resource- and KPI-aware AI infrastructure.
Intelligent workload placement across distributed sites
The NVIDIA AI Grid reference design provides a unified framework for building geographically distributed, interconnected, and orchestrated AI infrastructure. Figure 1 shows how existing network assets come together as an AI grid: