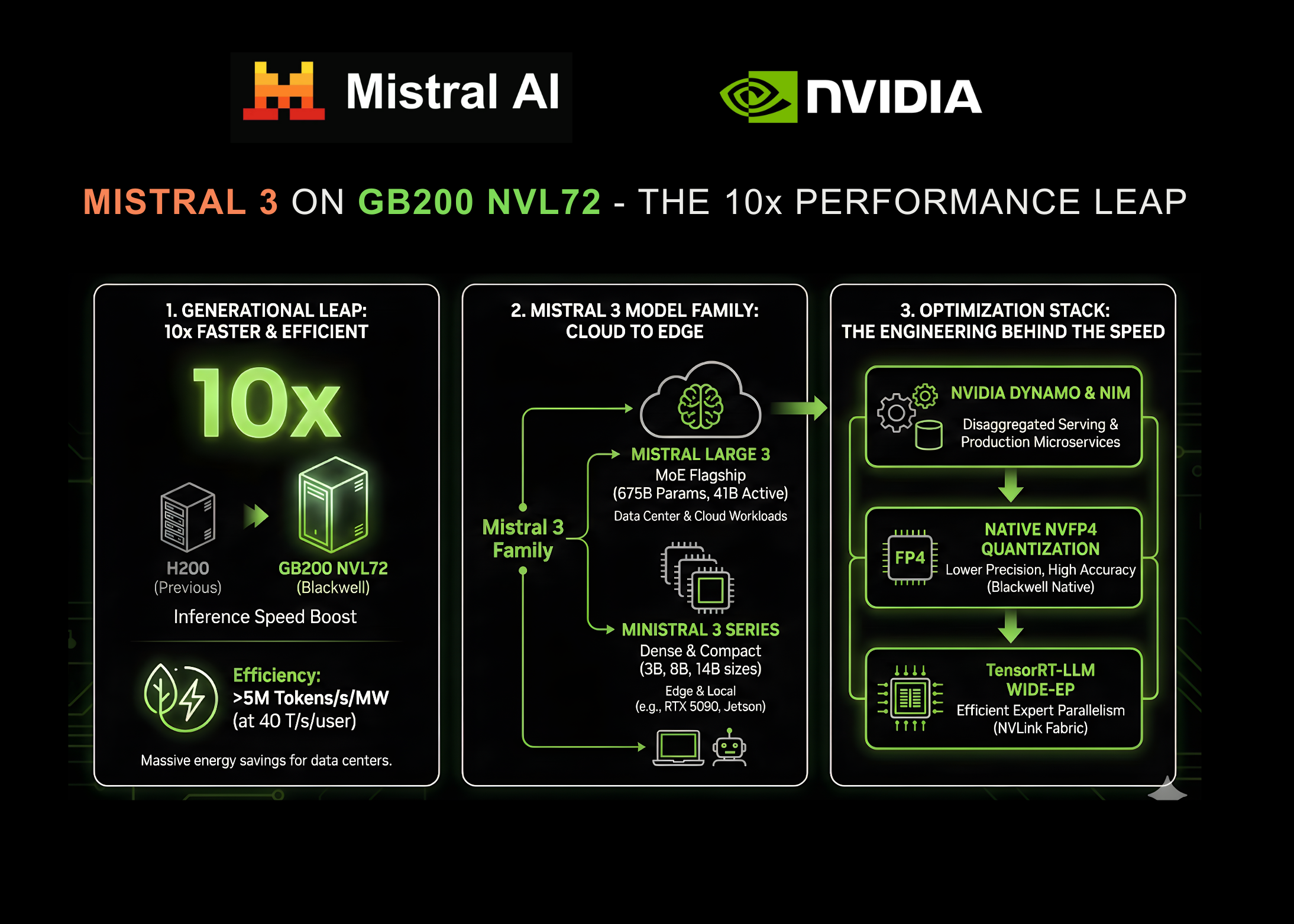
The new Mistral 3 open model family delivers industry-leading accuracy, efficiency, and customization capabilities for developers and enterprises. Optimized from NVIDIA GB200 NVL72 to edge platforms, Mistral 3 includes:
One large state-of-the-art sparse multimodal and multilingual mixture of experts (MoE) model with a total parameter count of 675B
A suite of small, dense high-performance models (called Ministral 3) of sizes 3B, 8B, and 14B, each with Base, Instruct, and Reasoning variants (nine models total)
All the models were trained on NVIDIA Hopper GPUs and are now available through Mistral AI on Hugging Face. Developers can choose from a variety of options for deploying these models on different NVIDIA GPUs with different model precision formats and open source framework compatibility (Table 1).
Mistral Large 3 Ministral-3-14B Ministral-3-8B Ministral-3-3B Total parameters 675B 14B 8B 3B Active parameters 41B 14B 8B 3B Context window 256K 256K 256K 256K Base – BF16 BF16 BF16 Instruct – Q4_K_M, FP8, BF16 Q4_K_M, FP8, BF16 Q4_K_M, FP8, BF16 Reasoning Q4_K_M, NVFP4, FP8 Q4_K_M, BF16 Q4_K_M, BF16 Q4_K_M, BF16 Frameworks vLLM ✔ ✔ ✔ ✔ SGLang ✔ – – – TensorRT-LLM ✔– – – Llama.cpp – ✔ ✔ ✔ Ollama – ✔ ✔✔ NVIDIA hardware GB200 NVL72 ✔ ✔ ✔ ✔ Dynamo ✔ ✔ ✔ ✔ DGX Spark ✔ ✔ ✔ ✔ RTX – ✔ ✔ ✔ Jetson – ✔ ✔ ✔ Table 1. Mistral 3 model specifications