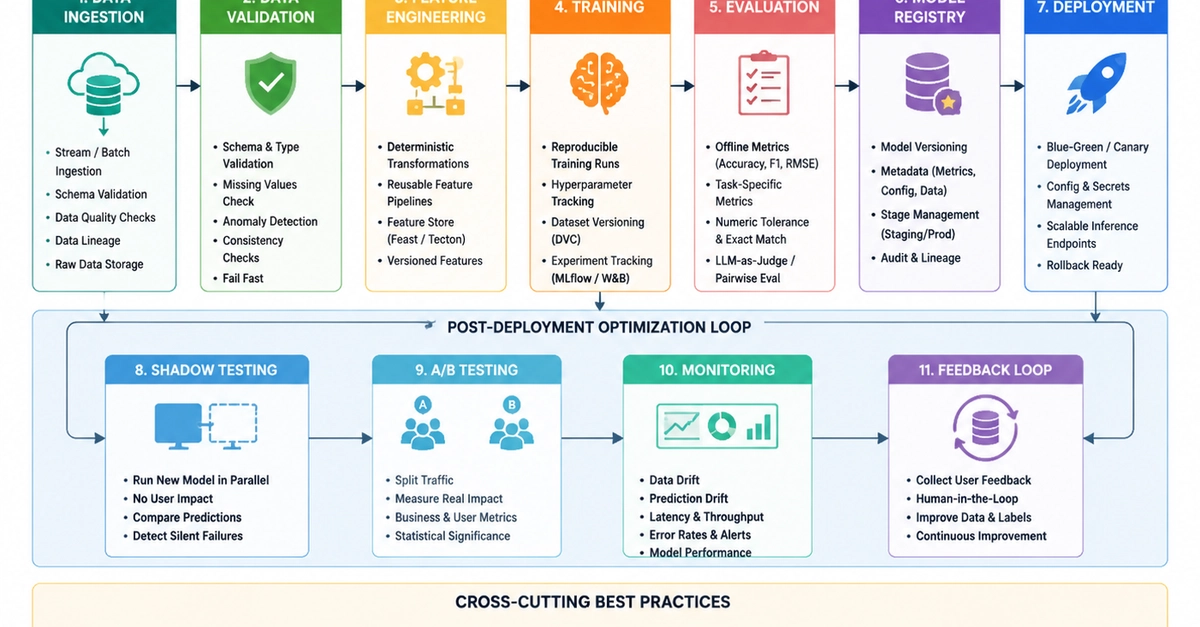
The path from a trained AI model to production should be smooth, but rarely is. Many teams invest weeks fine-tuning models, only to discover that exporting to a deployment format breaks layers, input shapes cause runtime failures, or version mismatches silently degrade performance. These issues are collectively known as pipeline friction, and they cost organizations time, money, and competitive advantage.
This post provides actionable best practices for eliminating the most common sources of friction in AI model serving pipelines. The results are concrete: APIs respond faster under real traffic. Each GPU carries more requests. Scaling up for peak hours is a smooth, low-stress effort. Cost per inference drops. And the deployments themselves stop being the part of every release that breaks.
What is pipeline friction in AI model serving?
Pipeline friction refers to any obstacle that slows or disrupts the journey of a model from training to production inference. Unlike bugs that produce clear error messages, friction often manifests as subtle inefficiencies: a model that consumes twice the expected GPU memory, for example, or an inference server that drops requests under load, or a deployment that works on one GPU architecture but fails on another.