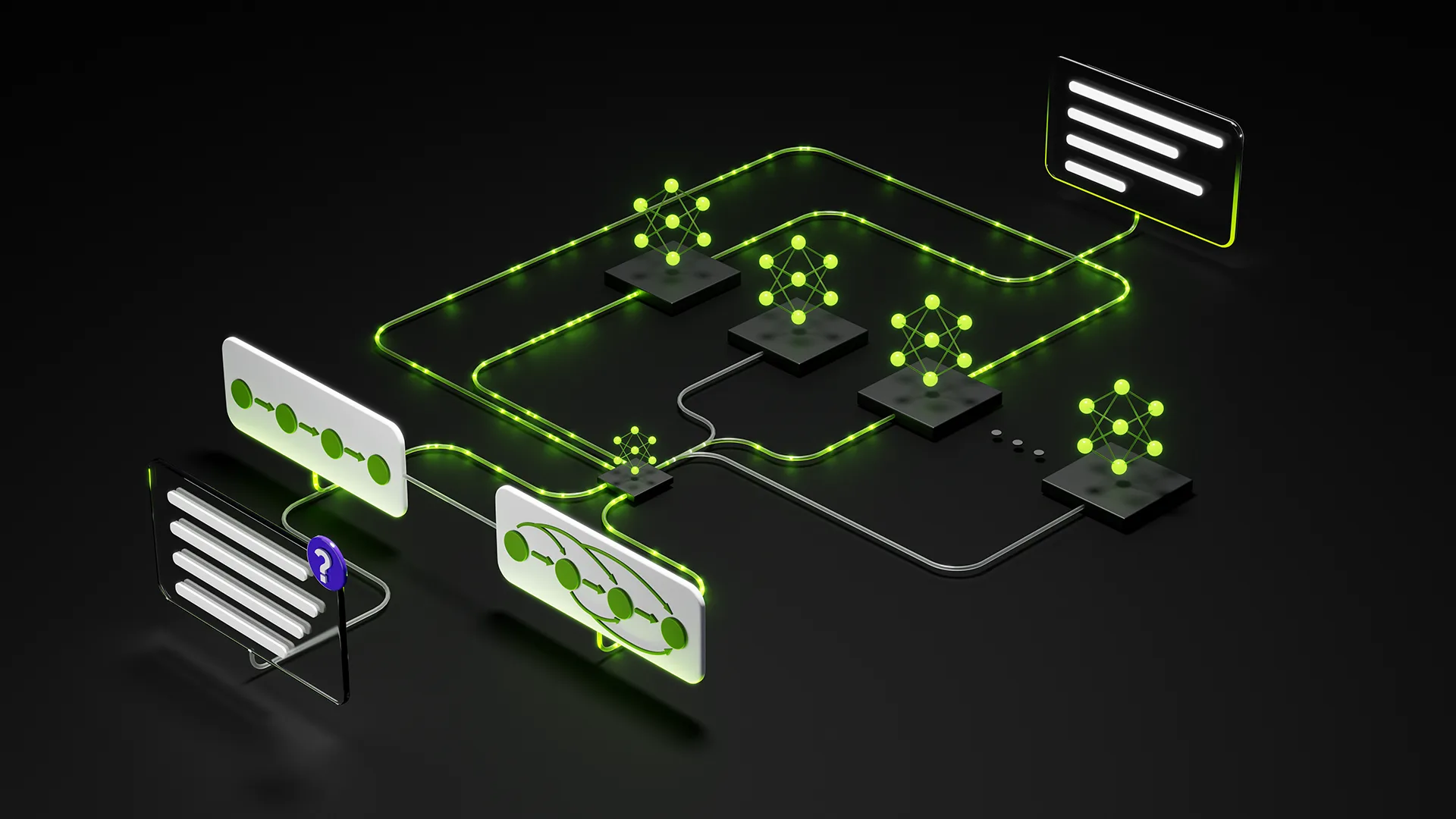
An agentic exchange must preserve a structured interaction: assistant turns interleave reasoning with one or more tool calls, and subsequent user turns return the corresponding tool results to the model context. Reasoning replay is model- and turn-dependent: some reasoning should be retained, while some should be dropped.
The inference engine is responsible for supporting this more expressive interaction model and for producing correctly segmented API results. Tool-call parsing and reasoning parsing need to happen before the attached harness consumes the response. High-value agentic workflows such as coding also depend on a responsive harness experience: reasoning segments, tool-call events, and request metadata need to stream back as the turn unfolds instead of arriving only after a final text response.
This post covers lessons from running real agentic clients against NVIDIA Dynamo: how we hardened parser and API coverage, improved streaming behavior, and extracted those parser layers into standalone reusable crates.
These changes build on the performance considerations outlined in our first post, which focused on the serving architecture underneath agentic inference: the frontend, router, and KV cache management. This follow-up focuses on correctness, user-experience equivalence, and performance.