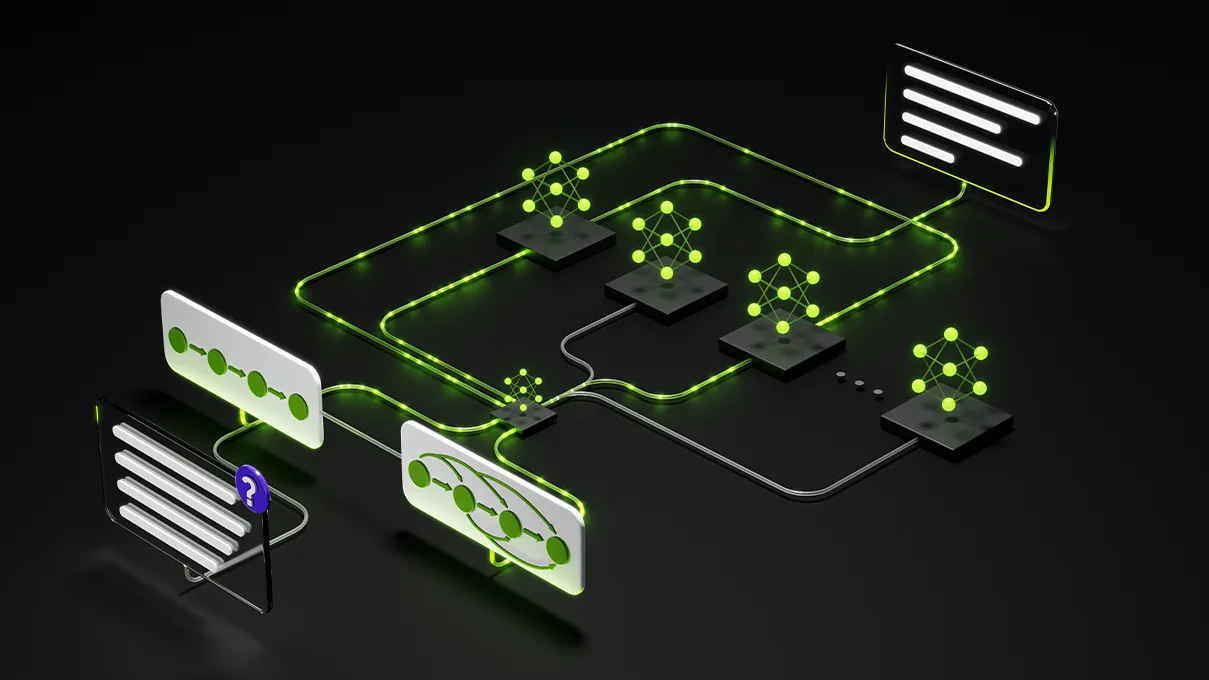
Agentic inference has fundamentally changed the runtime dynamics of inference workloads by introducing non-deterministic trajectories—actions, observations, and decisions that an AI agent produces while working through a task. These trajectories compound end-to-end latency across hundreds of inference requests per session.
NVIDIA Vera Rubin NVL72 handles the bulk of that inference load as the core compute engine of the NVIDIA Vera Rubin platform. The most demanding emerging multi-agent workloads require sustained low-latency and high-throughput generation on trillion-parameter MoE models with long-context windows.
Until now, no platform has served this emerging workload economically. NVIDIA Groq 3 LPX, paired with Vera Rubin NVL72, is the first to deliver both high throughput and low latency at this point on the Pareto curve.
This post explores how the NVIDIA Vera Rubin Platform solves this challenge through extreme co-design, combining high-throughput compute with low-latency, deterministic execution across hundreds to thousands of chips.
Why agentic workloads require predictable scale-up networking