Alexey Nizhegolenko
DevOps Engineer, AgentOps Engineer, AI Infrastructure Engineer
This is the second article in my series on self-hosting LLMs on GKE. In the first article I covered deploying Gemma4 26B with a 28,000 token context window. This time I'll show you something more impressive: openai/gpt-oss-20b running with a 128,000 token context on the same single L4 GPU.
The setup has been running in production since November 2025, for about 6 months, with no major incidents. That's the kind of track record worth writing about.
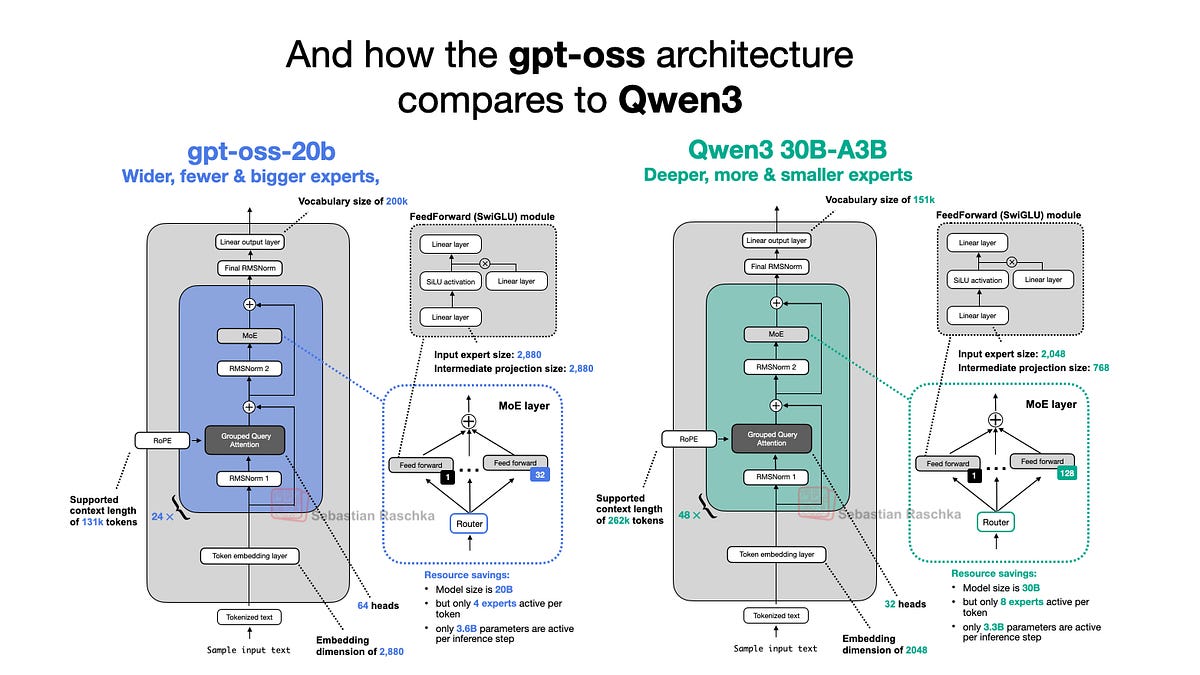
Why gpt-oss-20b?