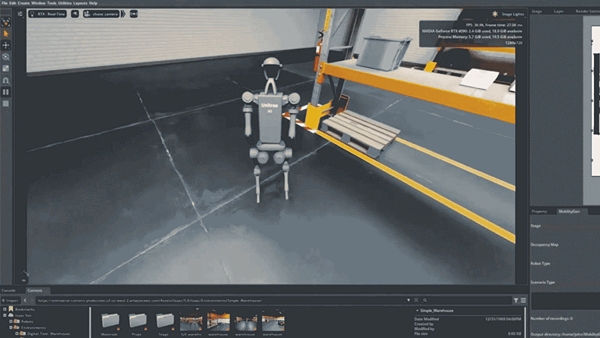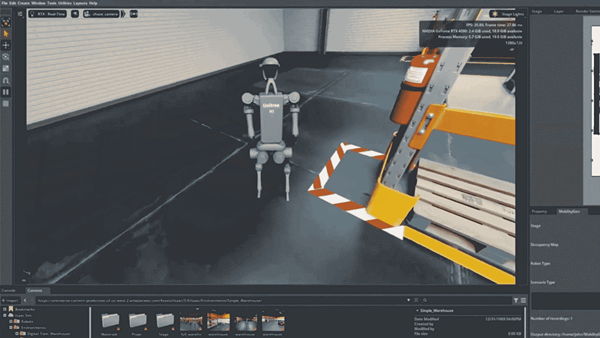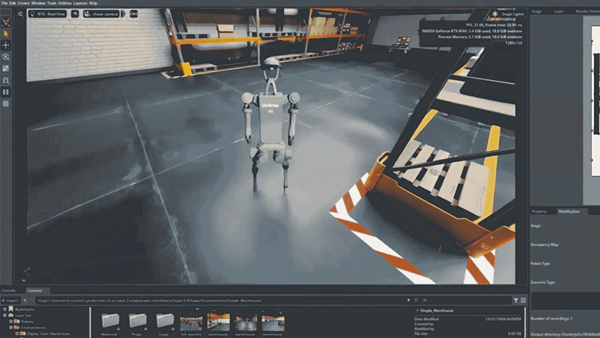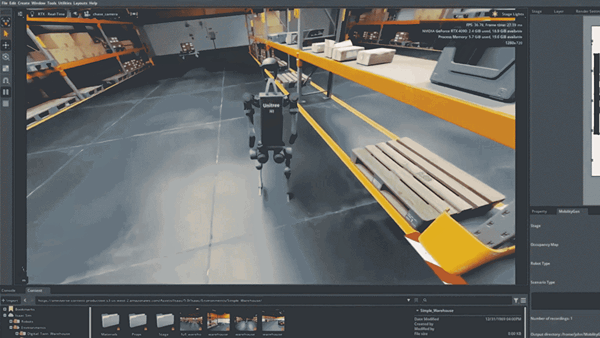
World models (systems that synthesize realistic video sequences from an initial image and a set of actions) are becoming central to embodied AI, simulation, and robotics research. The core challenge is scaling these systems to generate minute-long, high-resolution video without requiring prohibitively large clusters for both training and inference. Most competitive open-source baselines either require multi-GPU inference or sacrifice resolution to stay within compute budgets.
NVIDIA’s SANA-WM directly targets these bottlenecks. Built on the SANA-Video codebase and available through the NVlabs/Sana GitHub repository, it is a 2.6B-parameter Diffusion Transformer (DiT) trained natively for one-minute generation at 720p with metric-scale 6-DoF camera control. It supports three single-GPU inference variants: a bidirectional generator for high-quality offline synthesis, a chunk-causal autoregressive generator for sequential rollout, and a few-step distilled autoregressive generator for faster deployment. The distilled variant denoises a 60-second 720p clip in 34 seconds on a single RTX 5090 with NVFP4 quantization.
https://arxiv.org/pdf/2605.15178
The Architecture: Four Core Design Decisions