Home
Storia in 1 fonti
Optimizing inference speed and costs: Lessons learned from large-scale deployments
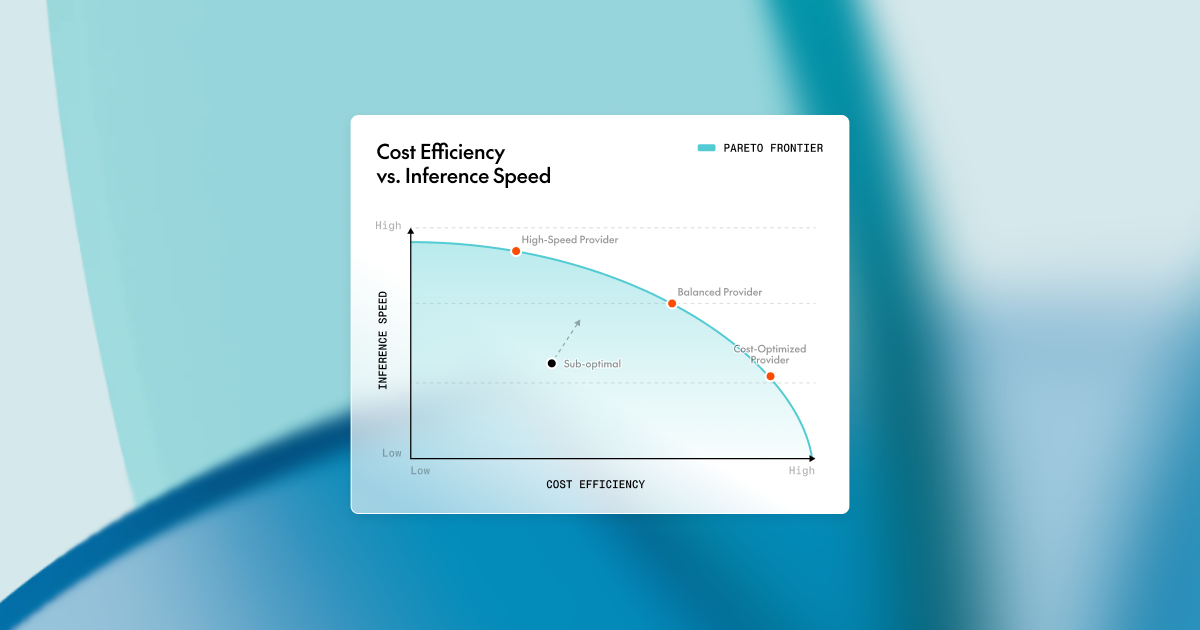
Learn how to reduce inference latency without massive cost using proven inference optimization tactics — improving throughput, GPU utilization, and cost efficiency while balancing throughput vs. latency tradeoffs.
Raccontata da together.ai
together.ai