HomeAI · summaries
Storia in 2 fonti
Building a personalized code assistant with open-source LLMs using RAG Fine-tuning
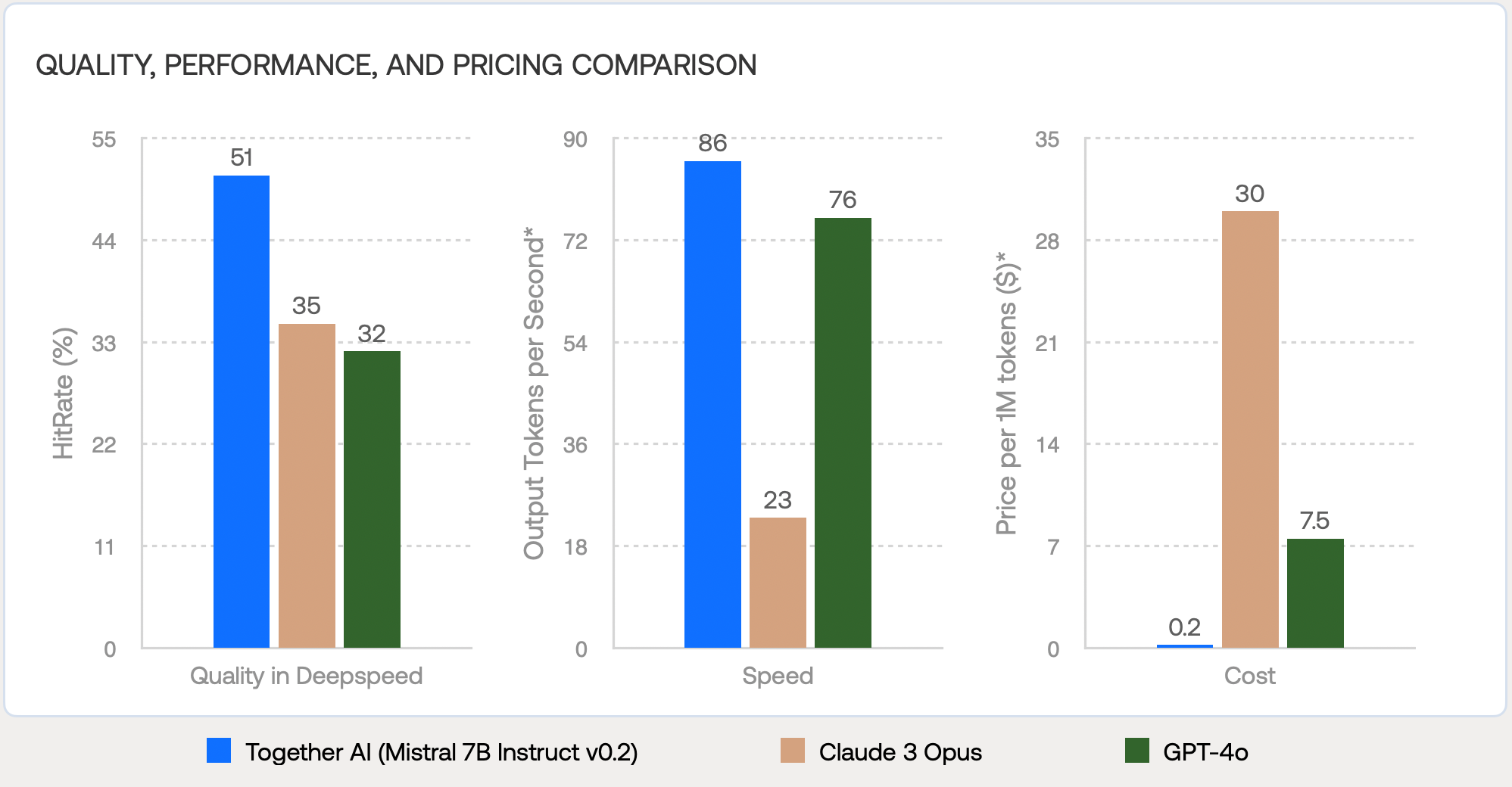
RAG fine-tuning combines code retrieval with model training, addressing the limitations of outdated knowledge and hallucinations in LLMs. Our experiments with fine-tuning Mistral 7B Instruct v0.2 on Together AI Platform show that RAG fine-tuned models achieve up to 16% better accuracy than Claude 3 Opus, while offering 3.7x faster speed and an astounding 150x cost reduction. Compared to GPT-4o, the models achieve up to 19% quality improvement, 1.1x faster speed at 37.5x cost reduction. Figure 1. Comparing RAG fine-tuned Mistral 7B Instruct v0.2 to Claude 3 Opus and GPT-4o in quality, speed, and cost*The data presented in this graph was sourced from Artificial Analysis for serverless models.OverviewLarge Language Models (LLMs) have shown promising capabilities on multiple applications such as code generation, task planning, and document understanding. Despite the impressive performance, these models often fall short due to two main reasons: hallucinations and outdated knowledge in the models. For example, LLMs are limited on generating code referencing specific codebases as it requires up-to-date code and accurate code structures [1,2,3].Retrieval-Augmented Generation (RAG) is a technique designed to address such limitations in language model capabilities by integrating retrieval methods into the text generation process. This approach involves two key phases: indexing and querying. In the indexing phase, which is typically conducted offline, external knowledge sources—such as internal documents—are divided into chunks. These chunks are then transformed into vectors using an embedding model then stored in a vector database. During the querying phase, relevant information is retrieved from this database and combined with the initial query in a specific format. This enriched input is then used by a generation model to produce the final output.The success of RAG critically depends on the effectiveness of the indexing, retrieval, and generation processes using the retrieved context. To enhance the indexing and retrieval stages, we partnered with Morph Labs, leveraging their advanced technologies in codebase search and synthetic data generation. For the generation portion, it was vital to ensure that the system could accurately utilize the retrieved context. Thus, we fine-tuned Mistral 7B Instruct v0.2 using Together's Fine-tuning API to ensure the model's responses are up-to-date by incorporating the latest coding standards and practices. The results of this fine-tuning have been remarkable, showing significant enhancements in the model's performance. Many instances of our fine-tuned models have demonstrated at par or better capabilities than GPT-4o and Claude 3 Opus in popular AI open source codebases.The Challenge of Code Generation with LLMsWhen using LLMs to generate codes, they have two primary issues:Hallucination: Existing LLMs are trained on large amounts of data to improve the generalization. However, with large-scaled data, LLMs may also learn a lot of noisy information with inaccurate knowledge or alignment. Also, with more generalized capabilities, LLMs might sacrifice their domain-specific knowledge, such as knowledge on specific codebases. These noisy training data and over generalization cause the LLMs to generate plausible but incorrect codes based on users queries.Outdated Information: As codebases evolve, the static knowledge of an LLM becomes less relevant, leading to recommendations that may not comply with the latest programming practices or library updates.Figure 2. The overall framework of RAG Fine-tuning on code generation during training and inferenceOnline repository-level fine-tuning with retrievalRAG is a popular technique to address these limitations, but existing open-sourced models are limited to utilize the retrieved information in the prompt with domain-specific knowledge or format. To improve the RAG performance, we studied the RAG fine-tuning method and applied it to code generation tasks. Unlike standard fine-tuning, this approach first retrieves relevant code snippets from a code repository based on each query. Then, the snippets serve as contextual grounding during the model's training phase, ensuring that generated code is not only accurate but also contextually appropriate based on up-to-date codebases. Figure 2 shows the overall framework for the RAG fine-tuning on code generation.Data Morph Labs generated synthetic datasets for training and evaluation where each sample contains a natural-language question and the correct answer. For each question, a set of code snippets retrieved via the Morph Code API are used as the RAG context and concatenated with the question-answer pairs. This allows the model to learn how to utilize real-time knowledge given in the query rather than relying on pre-existing data. The below example shows a sample for vLLM: Context:
Confronto fonti
2 prospettive sulla stessa storiaTimeline cronologica
- ·
together.ai
Building a personalized code assistant with open-source LLMs using RAG Fine-tuning
RAG fine-tuning combines code retrieval with model training, addressing the limitations of outdated knowledge and hallucinations in LLMs. Our experiments with fine-tuning Mistral…
- ·
mistral.ai

Evaluating RAG with LLM as a Judge | Mistral AI
The most powerful AI platform for enterprises. Customize, fine-tune, and deploy AI assistants, autonomous agents, and multimodal AI with open models.