Home
Storia in 1 fonti
Speculative decoding for high-throughput long-context inference
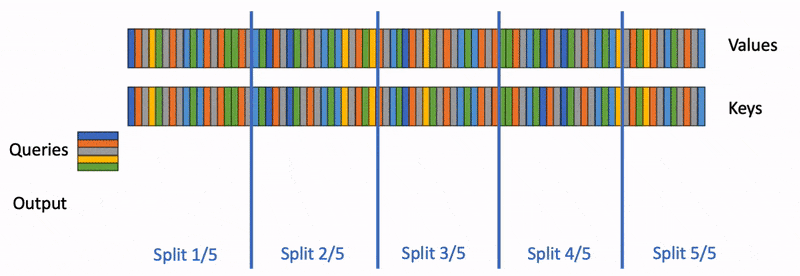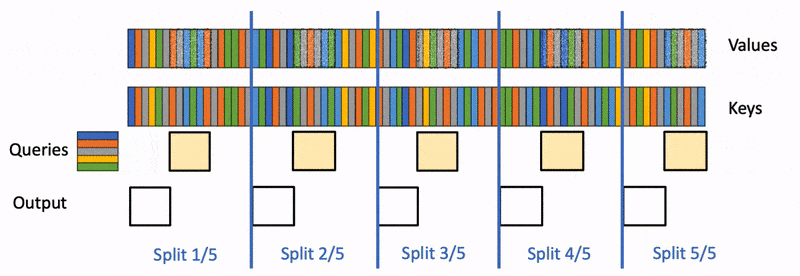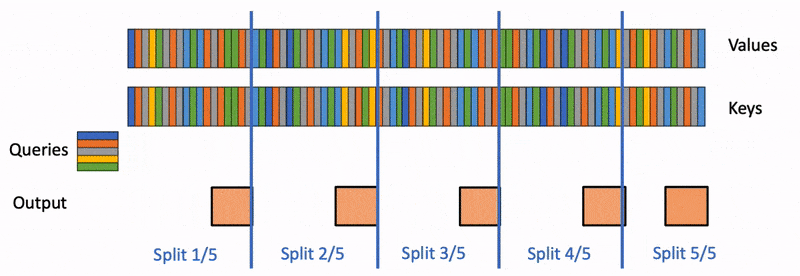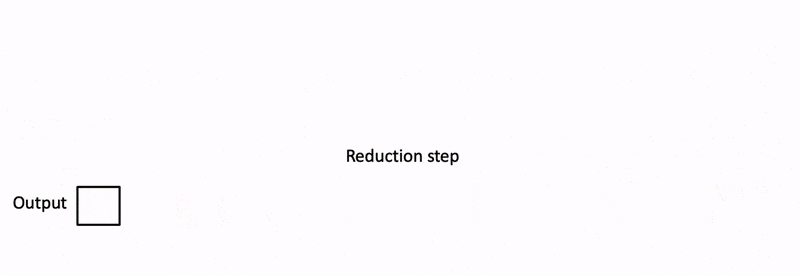
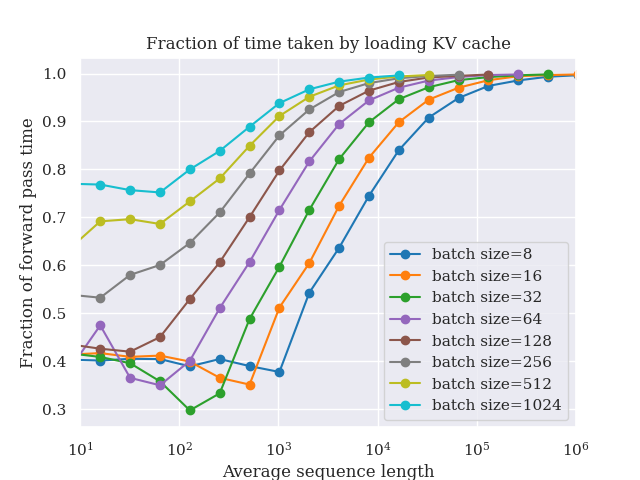
IntroductionThe amount of inference being performed with LLMs is growing dramatically across many different use cases, many of which utilize the ever-increasing context lengths supported by these models. Thus, maximizing the inference throughput of these models—including at long context—is becoming an increasingly important problem. Higher throughput enables lower price per token for consumers and lower carbon footprint per token. From a capability perspective, higher throughput at long context unlocks numerous applications such as information extraction from large sets of documents, synthetic data generation for LLM training/fine-tuning, extended user-assistant chats, and agentic workflows (which typically require numerous LLM calls per user request). These applications often involve processing very long input sequences (e.g., long documents or chat histories), requiring models to process thousands of tokens to deliver intelligent outputs. High throughput at long context is particularly technically challenging due to its huge memory requirements for the KV cache. Conventional wisdom (e.g., Chen et al., 2023; Li et al., 2024; Liu et al., 2024) is that in the high-throughput regime (i.e., large batch sizes), speculative decoding—which leverages underutilized GPU compute during memory-bound decoding—does not make sense, because decoding will be compute-bound and the GPUs will thus be fully utilized. Surprisingly, we show analytically and empirically that for large batch sizes, if the input sequences are long enough, decoding once again becomes memory-bound due to the large size of the KV cache. Building on this key observation, we demonstrate that speculative decoding can improve throughput and latency by up to 2x on 8 A100s in this large-batch, long-context setting.In this blogpost, we first do a deep dive into the forward pass time of a single transformer layer during autoregressive decoding. We show that at large batch sizes, if the context length is large enough, decoding becomes memory-bound, dominated by the time to load the KV cache. After presenting the above analysis, we describe how we can use speculative decoding to increase throughput in the long-context and large batch regime. In particular, we propose two algorithmic innovations:MagicDec: Taking advantage of the fact that the bottleneck during decoding at large batch + long context is loading the KV cache, MagicDec uses a fixed context window in the draft model to make the draft model many times faster than the target model (since the draft KV cache size is fixed). Furthermore, because in this regime loading the target model parameters is no longer the bottleneck, we can afford to use a very large and powerful draft model—we can even use the full target model as the draft model, as long as it uses a fixed context window. Based on these insights, MagicDec combines ideas from TriForce and StreamingLLM—as the draft model, it uses a StreamingLLM draft model (using sliding window attention + attention sink) with staged speculative decoding for further speedups during drafting. Intriguingly, in this regime, we get larger speedups the higher the batch size!Adaptive Sequoia trees: Leveraging our observation that there is a sequence length threshold above which decoding becomes memory bound—and that it becomes increasingly memory bound for even longer sequence lengths—we propose choosing the amount of speculation as a function of the sequence length (longer sequence length -> more speculated tokens). We leverage the Sequoia algorithm (see our paper, blog) to determine the tree structure for the speculated tokens that maximizes the expected number of generated tokens.We now jump into our deep dive of a single transformer layer.Deep dive: When is decoding for a single transformer layer dominated by loading the KV cache?Here, we analyze when the decoding forward pass time of a single transformer layer is dominated by loading the KV cache. We show that as the context length and batch size increase, most of the time is spent on loading the KV cache.For this analysis, we split the operations during the forward pass into two types: operations involving model parameters, and operations involving the KV cache. For each type of operation, we compute the number of FLOPS as well as the amount of memory that must be communicated. We note that while the operations involving model parameters become compute-bound as the batch size increases (as their arithmetic intensity equals the batch size $b$), operations involving the KV cache are always memory-bound (as their arithmetic intensity is constant, because each sequence in the batch has its own KV cache). Because the memory taken by the KV cache grows linearly with both the batch size and the average sequence length, whereas the model parameter FLOPS are constant with respect to the sequence length, the forward pass time becomes dominated by the loading of the KV cache as the average sequence length increases.Here, we will assume that we use a regular MLP, intermediate size=4*d, d=model dim, b=batch size, and n=current prefix length. We assume we are using GQA, where "g" corresponds to the ratio of query heads to key/value heads.
Raccontata da together.ai
together.ai
Timeline cronologica
- ·
Speculative decoding for high-throughput long-context inference
IntroductionThe amount of inference being performed with LLMs is growing dramatically across many different use cases, many of which utilize the ever-increasing context lengths…
- ·

SpecExec: Massively Parallel Speculative Decoding for Interactive LLM Inference on Consumer Devices
We introduce SpecExec, a new speculative decoding method that applies the classical approach of “speculative execution” to LLM inference. Using SpecExec, we attain inference…