Home
Storia in 1 fonti
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
FlashAttention-3 achieves up to 75% GPU utilization on H100s, making AI models up to 2x faster and enabling efficient processing of longer text inputs. It allows for faster training and inference of LLMs, supports lower precision operations for improved efficiency.
Raccontata da together.ai
together.ai
Timeline cronologica
- ·
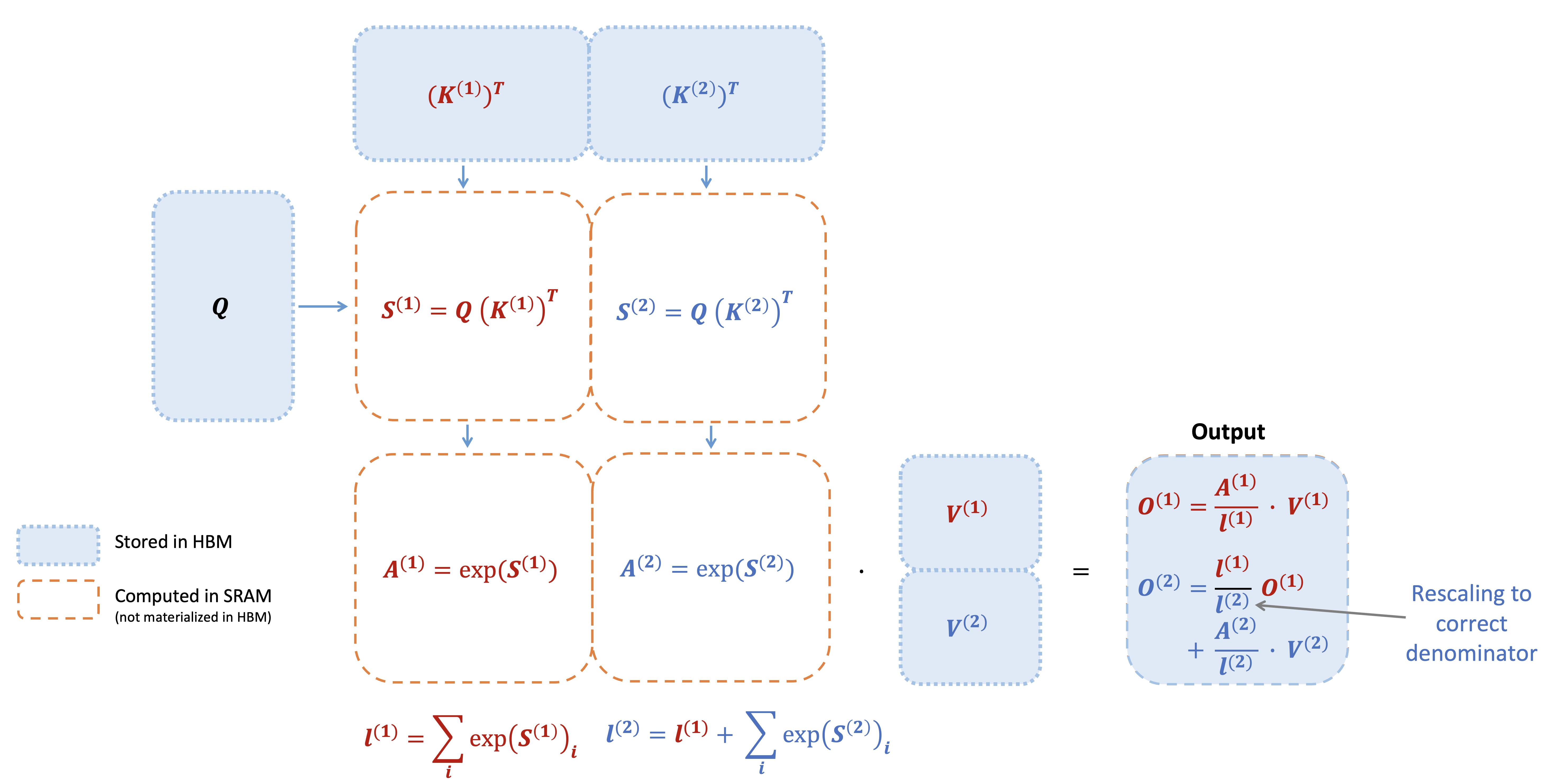
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
FlashAttention-3 achieves up to 75% GPU utilization on H100s, making AI models up to 2x faster and enabling efficient processing of longer text inputs. It allows for faster…
- ·
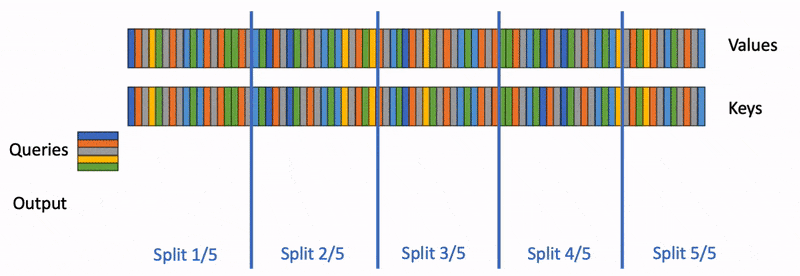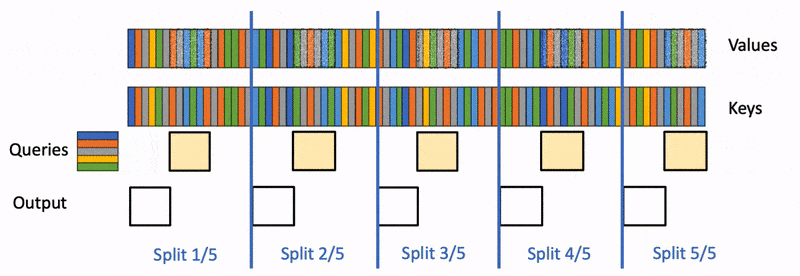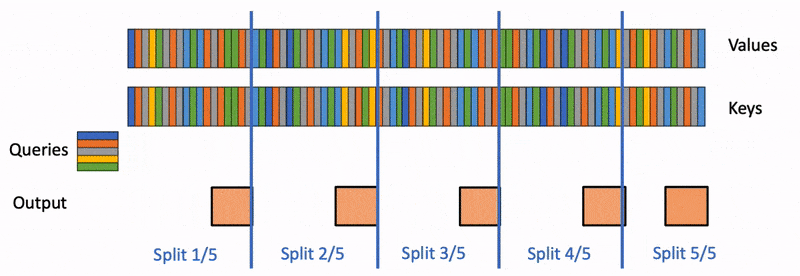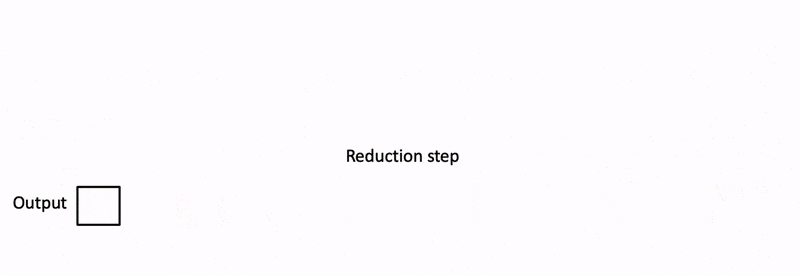
Flash-Decoding for long-context inference
Large language models (LLM) such as ChatGPT or Llama have received unprecedented attention lately. However, they remain massively expensive to run. Even though generating a single…