HomeAI · summaries
Storia in 2 fonti
Why MoE models get more from speculative decoding
MoE models enhance speculative decoding through bandwidth-bound sweet spots, expert routing correlation reducing unique weight loading, and fixed-overhead amortization at low batch sizes.
Confronto fonti
2 prospettive sulla stessa storiaTimeline cronologica
- ·
cohere.com
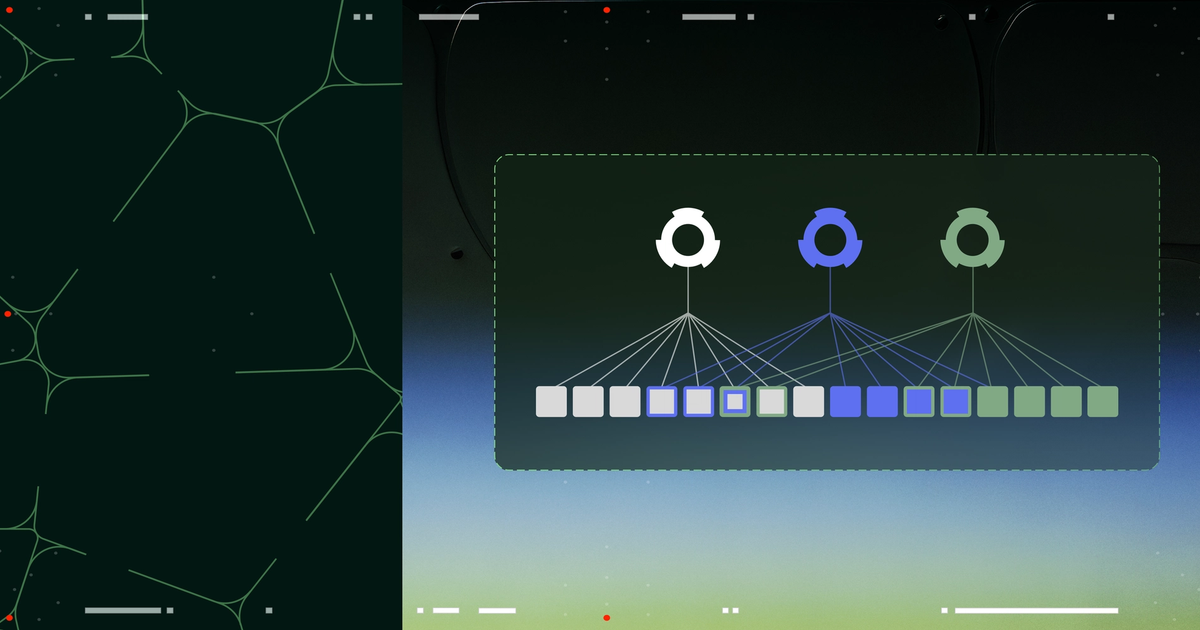
Why MoE models get more from speculative decoding
MoE models enhance speculative decoding through bandwidth-bound sweet spots, expert routing correlation reducing unique weight loading, and fixed-overhead amortization at low…
- ·
redis.io

Speculative decoding: how it works & when to use it
Learn how speculative decoding speeds up LLM responses, when batch size works against it, and how it pairs with semantic caching in a layered inference stack.