Home
Storia in 1 fonti
Cracking the Coding Evaluation | Tabby AI coding assistant
Tabby offers an open-source alternative solution to GitHub Copilot with easy setup and self-host options. We embrace an open ecosystem to support major open source coding LLMs (e.g. StarCoder, CodeLlama, WizardCoder, etc.), and enable easy integration of proprietary models. In addition, Tabby performs retrieval-augmented code completion to suggest code from your private codebase. We firmly believe in the continuous advancement in open source coding LLMs, yet we need quantitative measurements to guide the direction of product improvement, and help developers decide their model of choice.Evaluation coding LLMs has also been a hot topic in academics. Many different metrics targeting different coding tasks have been proposed over the past year. At Tabby, we prioritize on metrics that best resemble real-world development workflow, and of course, the metrics should be constructed with non-biased data sources. In this blogpost, we will discuss our thoughts for desired code completion benchmarks, and also review latest academic progress in this area.Exisiting ParadigmsExisting coding LLM benchmark mostly focus on Pass@k metric - generating k code samples and measuring how often the results successfully pass given unit tests. OpenAI initially introduced this metric in Evaluating Large Language Models Trained on Code in July 2021, along with the release of HumanEval bechmark dataset.🤖 HumanEvalHumanEval is a hand-crafted dataset, consisting of 164 Python programming problems with unit tests. An example task looks like:from typing import List
Raccontata da tabbyml.com
tabbyml.com
Timeline cronologica
- ·
Cracking the Coding Evaluation | Tabby AI coding assistant
Tabby offers an open-source alternative solution to GitHub Copilot with easy setup and self-host options. We embrace an open ecosystem to support major open source coding LLMs…
- ·
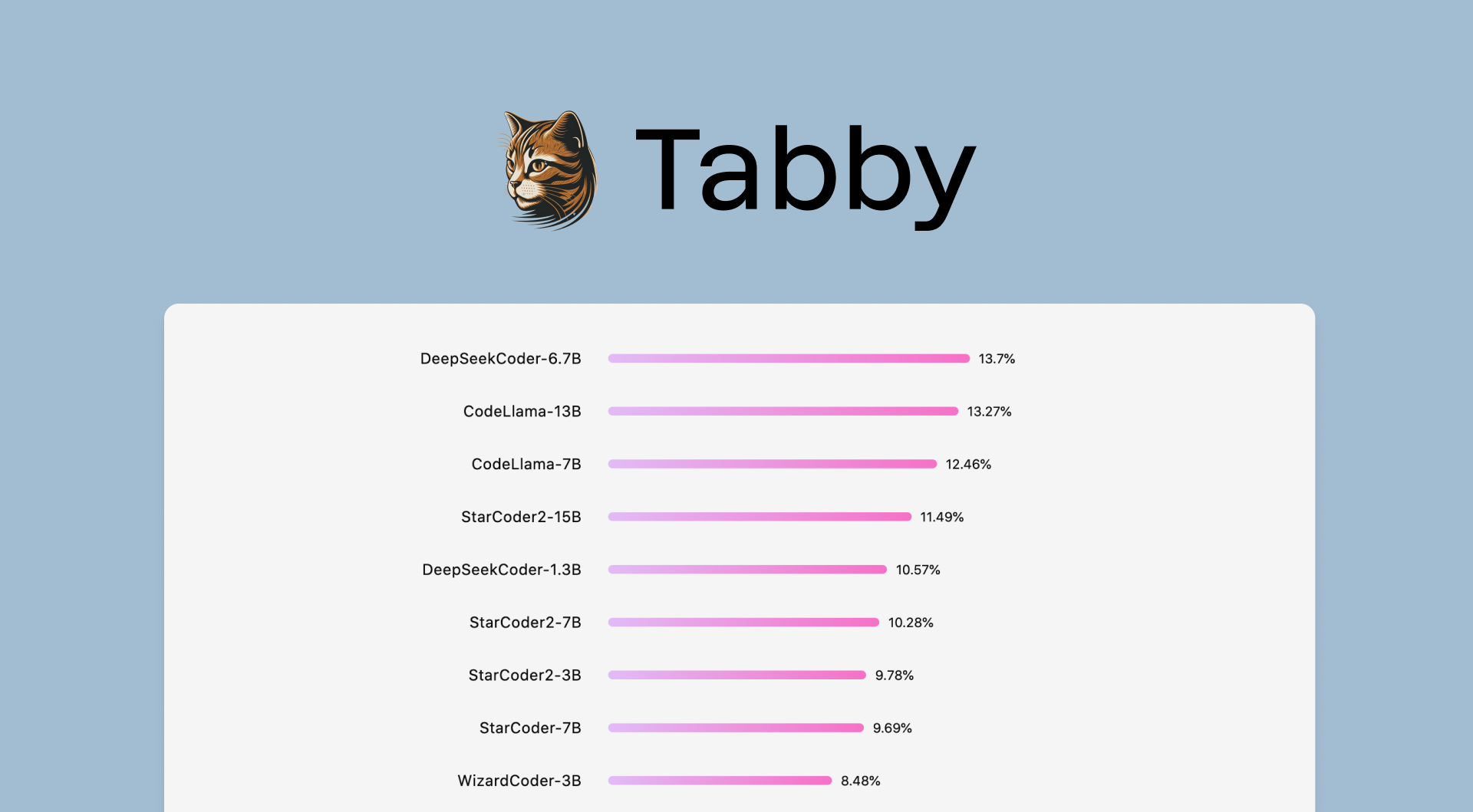
Introducing the Coding LLM Leaderboard | Tabby AI coding assistant
In our previous post on Cracking the Coding Evaluation, we shed light on the limitations of relying on HumanEval pass@1 as a code completion benchmark. In response, we've launched…
- ·
Repository context for LLM assisted code completion | Tabby AI coding assistant
Using a Language Model (LLM) pretrained on coding data proves incredibly useful for "self-contained" coding tasks, like conjuring up a completely new function that operates…