Home
Storia in 1 fonti
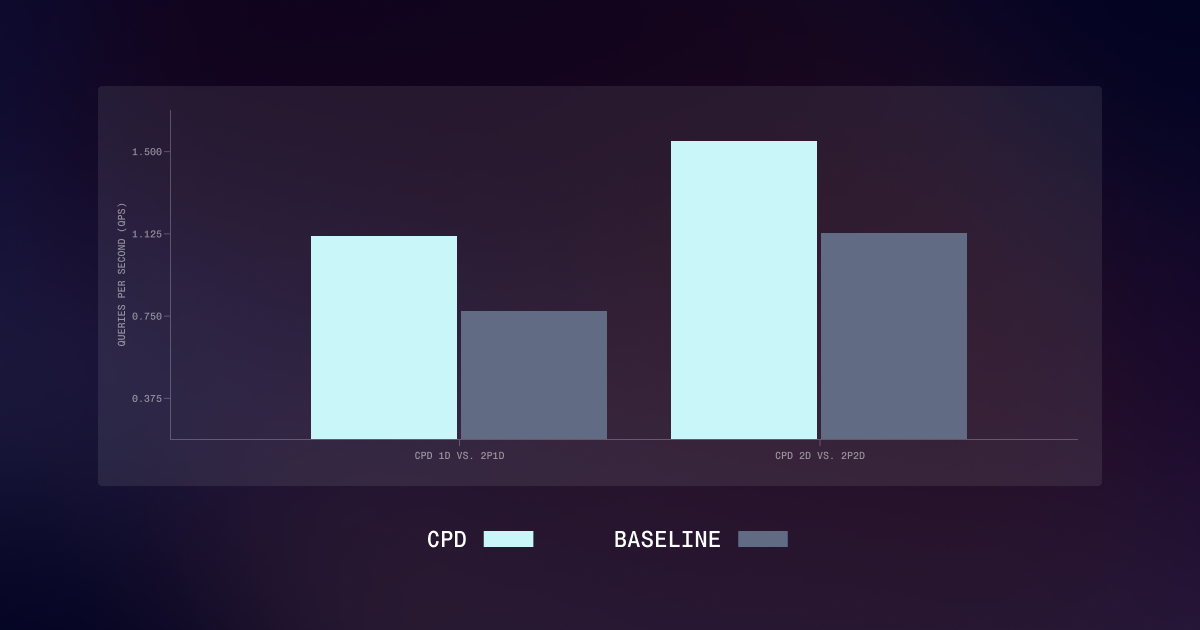
Cache-aware prefill–decode disaggregation (CPD) for up to 40% faster long-context LLM serving
Serving long prompts doesn't have to mean slow responses. Learn how Together AI's CPD architecture separates warm and cold inference workloads to deliver 40% higher throughput and dramatically lower time-to-first-token for long-context LLM serving.
Raccontata da together.ai
together.ai