Home
Storia in 1 fonti
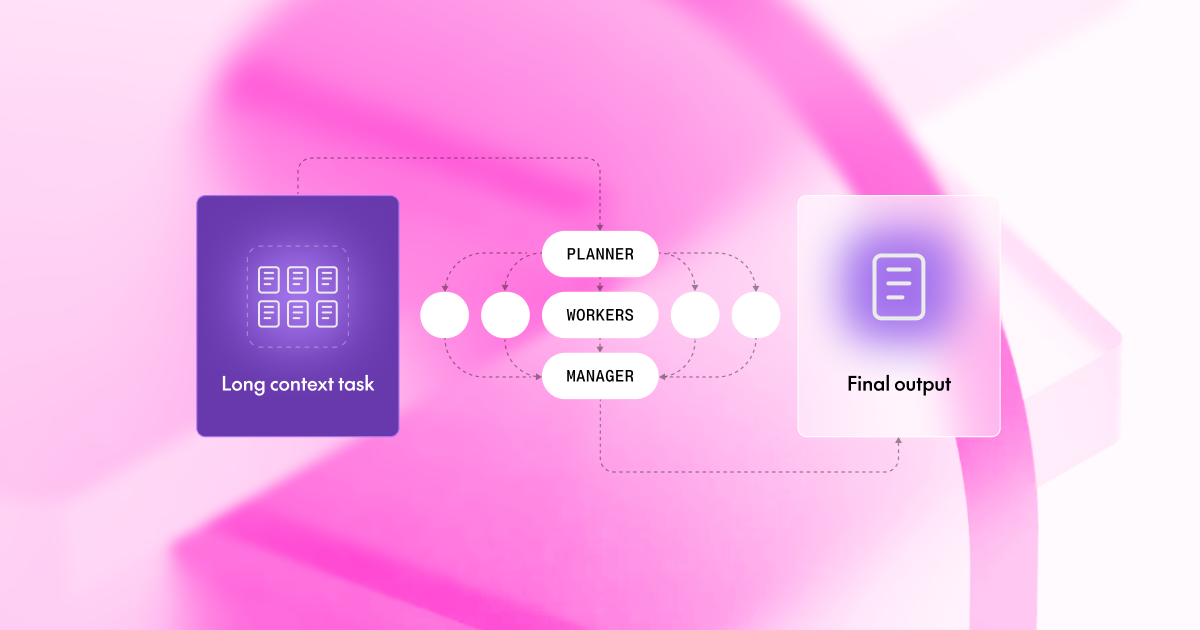
Plan, divide, and conquer: How weak models excel at long context tasks
As context windows grow, LLM performance degrades in unexpected ways. We show how a "Divide & Conquer" framework — breaking long documents into parallel chunks with a planner, workers, and manager — lets smaller models like Llama-3-70B and Qwen-72B outperform GPT-4o single-shot.
Raccontata da together.ai
together.ai
Timeline cronologica
- ·
Plan, divide, and conquer: How weak models excel at long context tasks
As context windows grow, LLM performance degrades in unexpected ways. We show how a "Divide & Conquer" framework — breaking long documents into parallel chunks with a planner,…
- ·

Long Context Fine-Tuning: A Technical Deep Dive
The landscape of Large Language Models (LLMs) is rapidly evolving, with context lengths expanding from a few thousand tokens a year ago to millions of tokens now. This increase in…