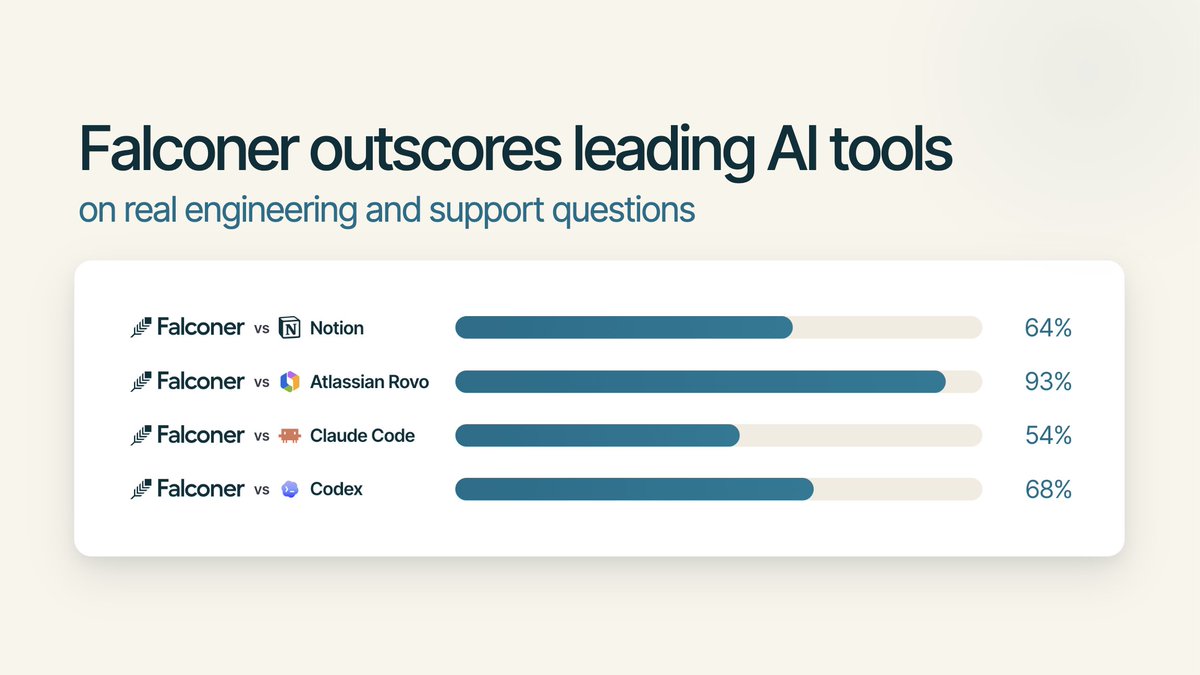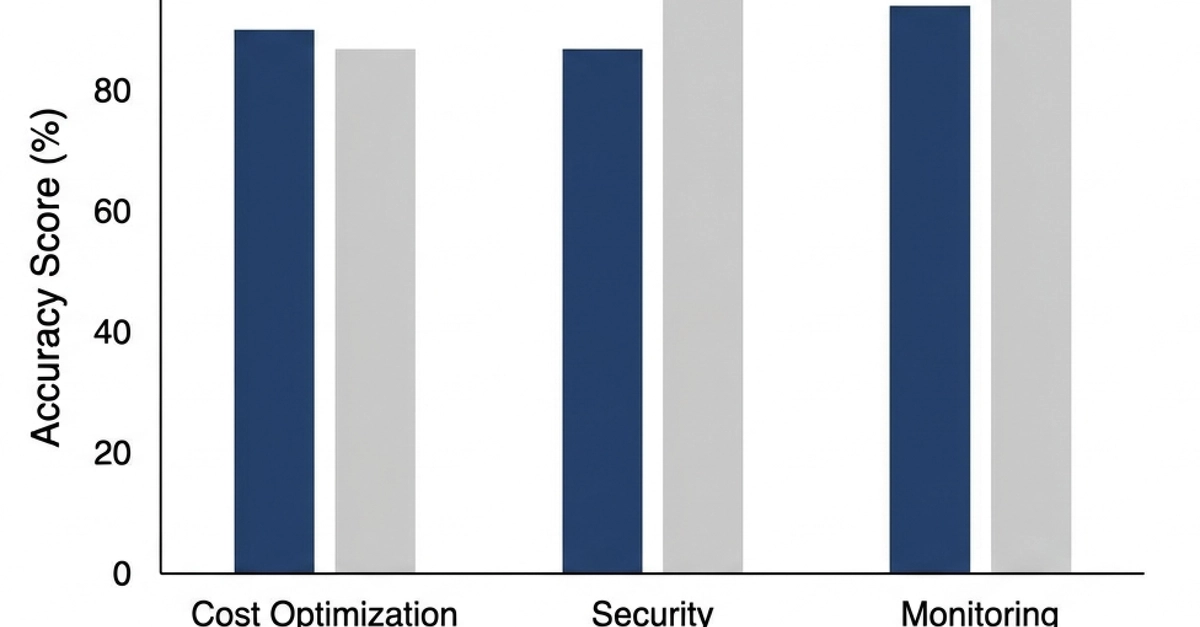
AI capability is jagged, not uniform. So the question is: how does your favorite harness (Codex, Claude Code...) fare on real cloud work?
A harness can top the coding benchmarks and still hallucinate resources that don't exist. And while there are established benchmarks for coding, computer use, and general reasoning, there's none for the work cloud teams actually delegate: cloud management tasks.
We're building that benchmark. Codex and Claude Code are on the rig now, others in the pipeline. Task 1 runs on AWS; the template is cloud-agnostic, with Azure and GCP replays to follow. This post is the methodology and an open invitation to tell us what to cover next.
The methodology
IaC is the answer key. We use Terraform to build the resources, so its outputs are the ground truth: exact resource IDs for what should be found and what must not be flagged. No human labeling, nothing to drift, and anyone can deploy the same stack and reproduce the result.