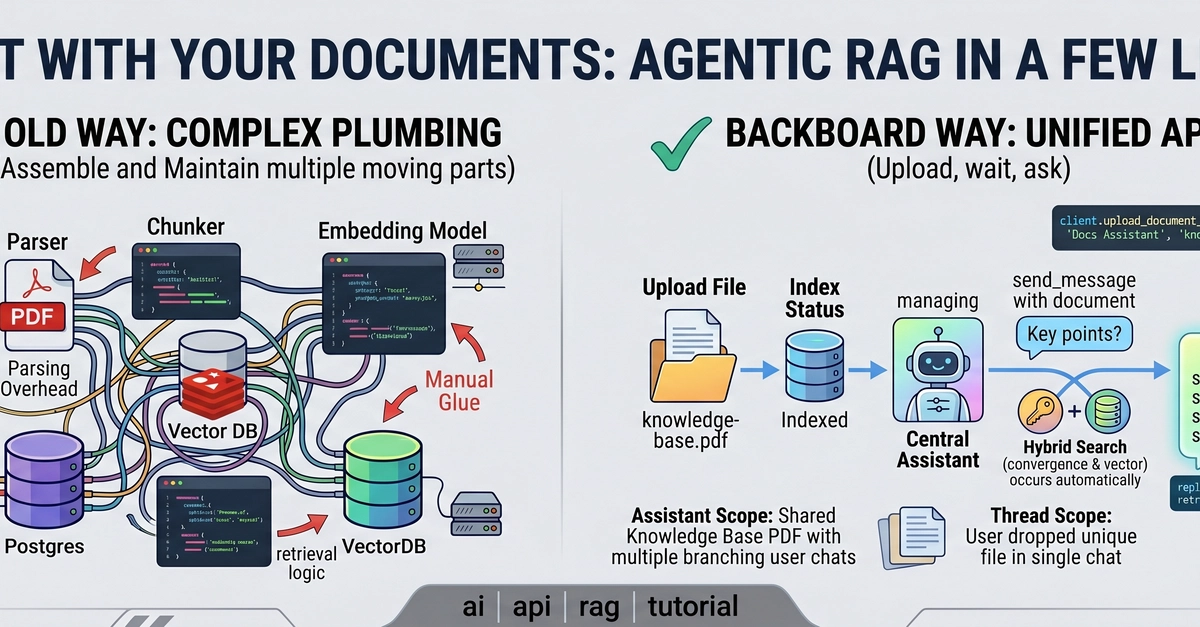
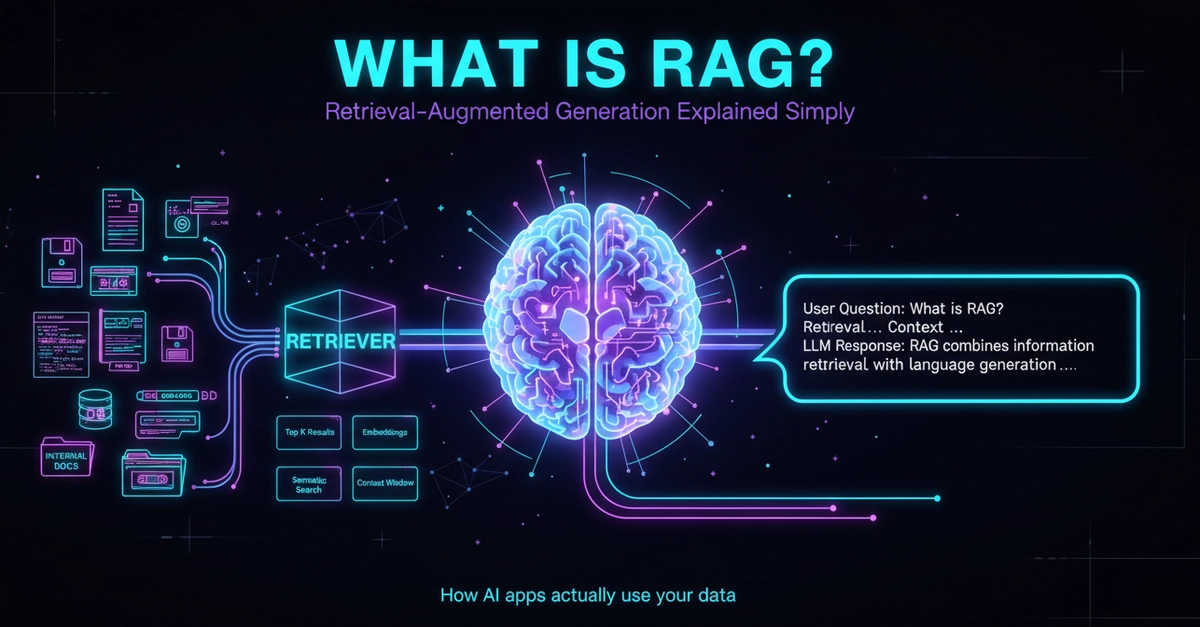
Want to build an AI assistant that talks to your company documents? First you need to answer one question: which RAG method actually works best on YOUR data?
RAG (Retrieval-Augmented Generation) works roughly like this: your documents are read, split into small pieces (chunks), and each piece is converted into a numerical vector (embedding) stored in a database. When a user asks a question, the system finds the most relevant pieces and feeds only those to the model. The model never sees the whole document — only what matters. Accuracy goes up, cost goes down.
The hard part: there are dozens of options at every step. Which parser? What chunk size? Which embedding model? Should you use a reranker? BM25, vector search, or hybrid? The answers change from dataset to dataset — there is no single "best for everyone" combination.
The good news: there are open-source tools that find the answer for you — by testing. I dug into three of them.
1. AutoRAG (Marker-Inc-Korea)