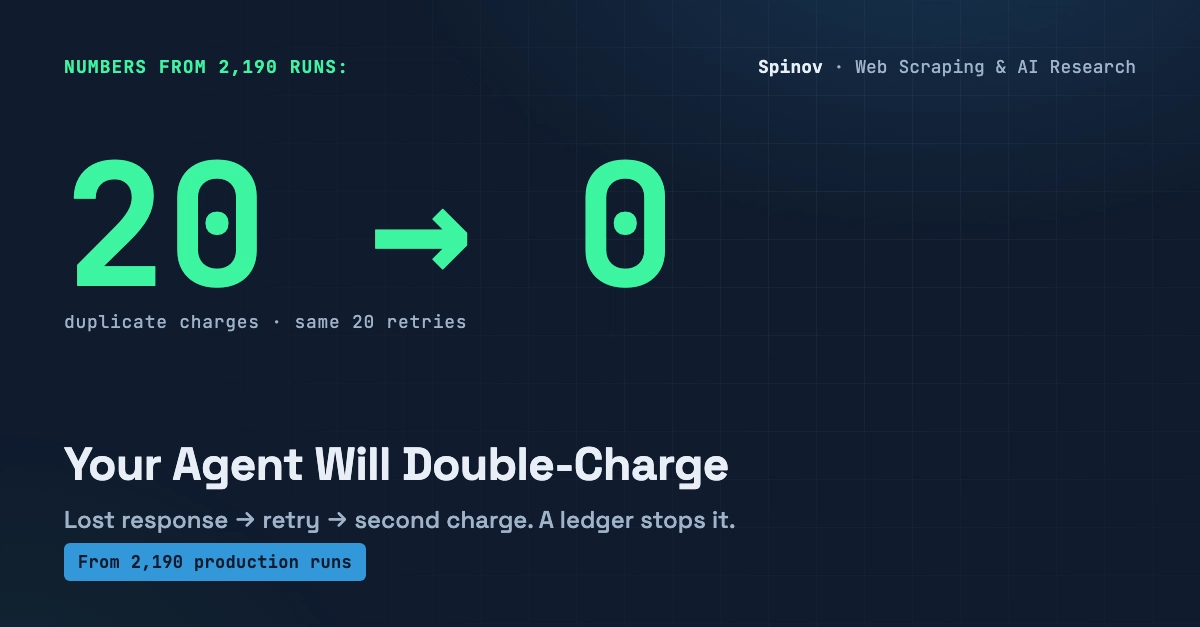
Your agent calls a tool. The tool times out at the network layer but actually succeeds on the server. Your harness sees no response, so it retries. Now charge_customer ran twice, send_email fired twice, and create_ticket left two tickets. The model did nothing wrong. Every eval you have is green. And a customer just got billed $198 for a $99 plan.
This is the failure mode nobody puts in a demo, because demos don't retry and demos don't have side effects that matter. Production has both. If your agent takes actions — not just generates text — then retry safety is not a nice-to-have, it is the difference between an autonomous system and a liability with a scheduler.
I want to argue two things. First: side-effect safety is a Tier 1 evaluation problem, not a prompt problem. Second: you cannot even see this class of bug without a trace of what the agent actually did, which is where the eval story and the observability story become the same story.
Why the model can't save you here
The instinct is to make the agent smarter. "Tell it to check whether the charge already went through before retrying." Please don't. You are asking a non-deterministic component to enforce an invariant that must hold every single time. The model will comply 95% of the time and the other 5% is a chargeback.