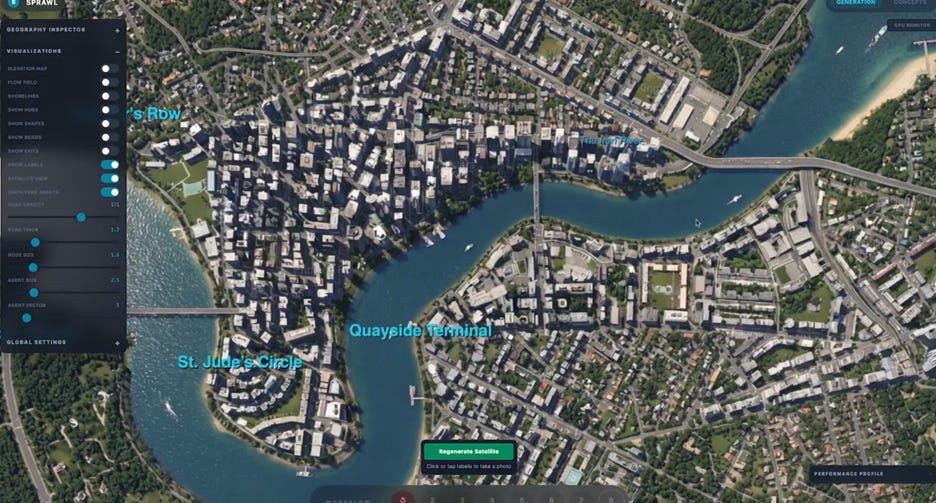
I’ve been testing every major frontier model release since the start of the year, and when Anthropic dropped Sonnet 5, I wanted more than a vibe check. I got tired of one-off tests I couldn’t repeat or compare over time, so I built something better: the How I AI Bench, a repeatable eval harness I constructed live using Claude Code while recording this episode. I ran Sonnet 5 blind against four other frontier models (Sonnet 4.6, Opus 4.8, GPT-5.5, and Gemini 3 Pro) across PRD quality, prototype generation, agentic task completion, and agent personality. The results were not what I expected.What Anthropic claims Sonnet 5 improves over Sonnet 4.6, and where the benchmark data actually backs that upHow I built the How I AI Bench in under 45 minutes using Claude Code, starting from my own stored session historyWhy I combined human vibe scoring (70%) with LLM as judge scoring (30%) instead of trusting either aloneHow to set up a local HTML scoring page so you can rate AI outputs on gut feel and export those scores as JSONWhich model I recommend for PRDs, which for complex prototypes, and which for chatting with an agent dailyRunway—The creative AI platform for images, video and moreHyperagent—Deploy fleets of agents that handle real work(00:00) Sonnet 5 is out(01:55) What Anthropic claims(04:02) Why I’m done with one-off vibe checks(05:05) Building the How I AI Bench live with Claude Code(07:42) The scoring system(10:43) Agent voice eval(11:57) Quick recap(13:58) Results: The How I AI index leaderboard(21:21) What I’m improving for the next run(22:16) Generating a Claire-weighted index(23:53) Model-by-task recommendations• Claude Sonnet 5: https://www.anthropic.com/news/claude-sonnet-5• Claude Opus 4.8: https://www.anthropic.com/news/claude-opus-4-8• GPT-5.5 (OpenAI): https://openai.com/index/introducing-gpt-5-5/• Gemini 3 Pro (Google DeepMind): https://deepmind.google/models/gemini/pro/• Cursor: https://www.cursor.com/• SWE-bench Pro (agentic coding benchmark referenced): https://www.swebench.com/ChatPRD: https://www.chatprd.ai/Website: https://clairevo.com/LinkedIn: https://www.linkedin.com/in/clairevo/X: https://x.com/clairevoProduction and marketing by https://penname.co/. For inquiries about sponsoring the podcast, email [email protected].
Sonnet 5 review: I ran 64 generations to find out if it's worth it
Watch now | 🎙 I built the How I AI Bench live using Claude Code, ran 5 frontier models through 64 blind prototype generations, PRDs, and agent voice tests, and the results surprised even me
306 words~1 min read