I've been building on DynamoDB since around 2015, and these days I build tools for it: dynoxide, a DynamoDB engine, and Nubo, a native client. So I'm not neutral about it. It's the first database I reach for, and with reason - the operational overhead is close to nil, no connections to pool or instances to size, and it holds the same single-digit-millisecond reads whether the table has a thousand items or a billion. The data modelling is a craft, and a satisfying one.
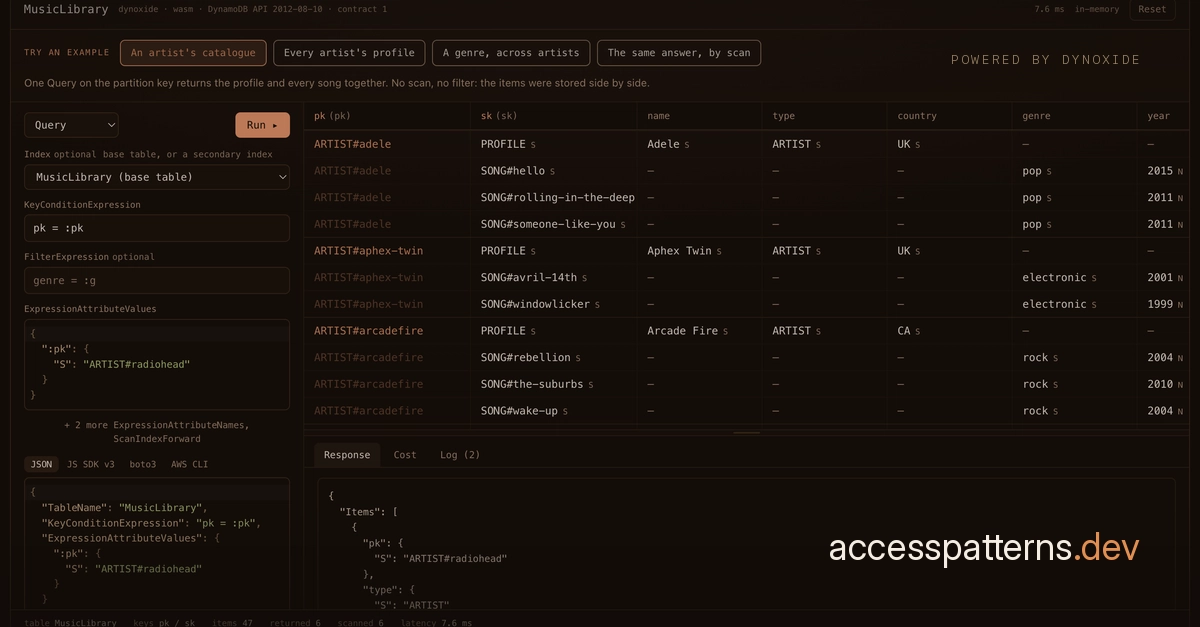
It's also one of the harder databases to learn, and that's the part I keep coming back to. DynamoDB punishes the instincts you bring from SQL. You don't normalise and join at read time; you work out the questions your app will ask first, and shape the data around those access patterns, until one table answers all of them. It's a real shift in how you think, and it's where a lot of people bounce off - it feels backwards right up until it clicks.
The people who teach it best all teach it the same way. Alex DeBrie's The DynamoDB Book, the arc.codes team's examples, Rick Houlihan's re:Invent talks - the legendary ones, where he models half a dozen access patterns onto a single table at a hundred miles an hour - none of them hand you rules to memorise. They show you patterns and make you run them. I learned a lot of my DynamoDB from all three, and it stuck because I was building as I went.





