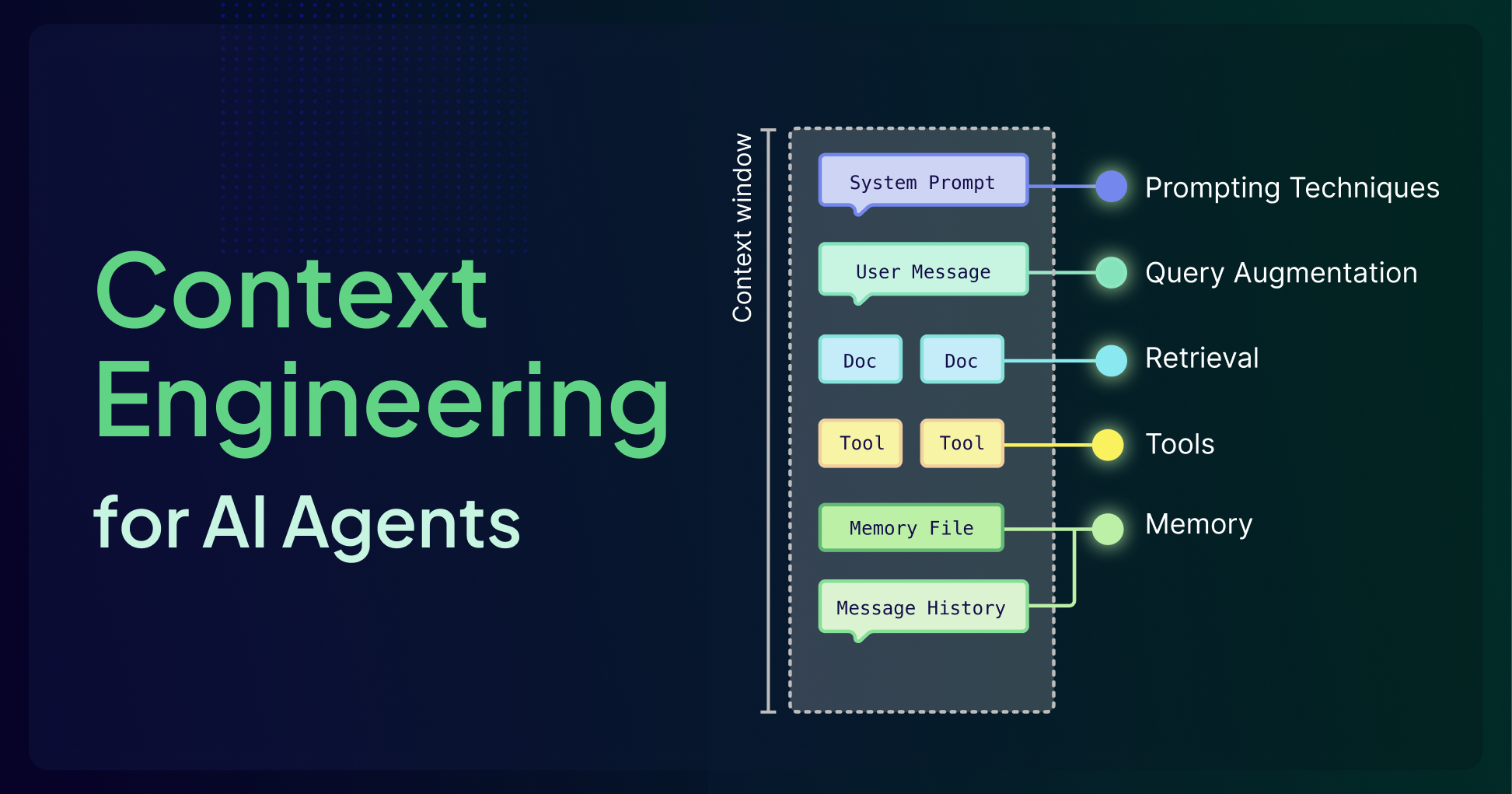
Prompt engineering asks: how do I phrase this instruction? Context engineering asks: what information does the model need, in what form, in what order, and how much of it — to produce a correct answer?
For a long time, the implicit mental model was: give the LLM more context and it performs better. This is wrong. A 20,000-token window stuffed with weakly relevant content produces worse answers than a 4,000-token window with precisely curated information. Larger windows do not eliminate context quality problems — they amplify them.
The Context Window Is a Budget
Treat it as a budget with competing line items, not a container you fill. Start with the total window, subtract fixed allocations (system prompt, output reserve, safety margin), and what remains is your dynamic budget split across retrieved chunks, conversation history, and memory.
The first question should always be: "can we get better at selecting less, rather than including more?"