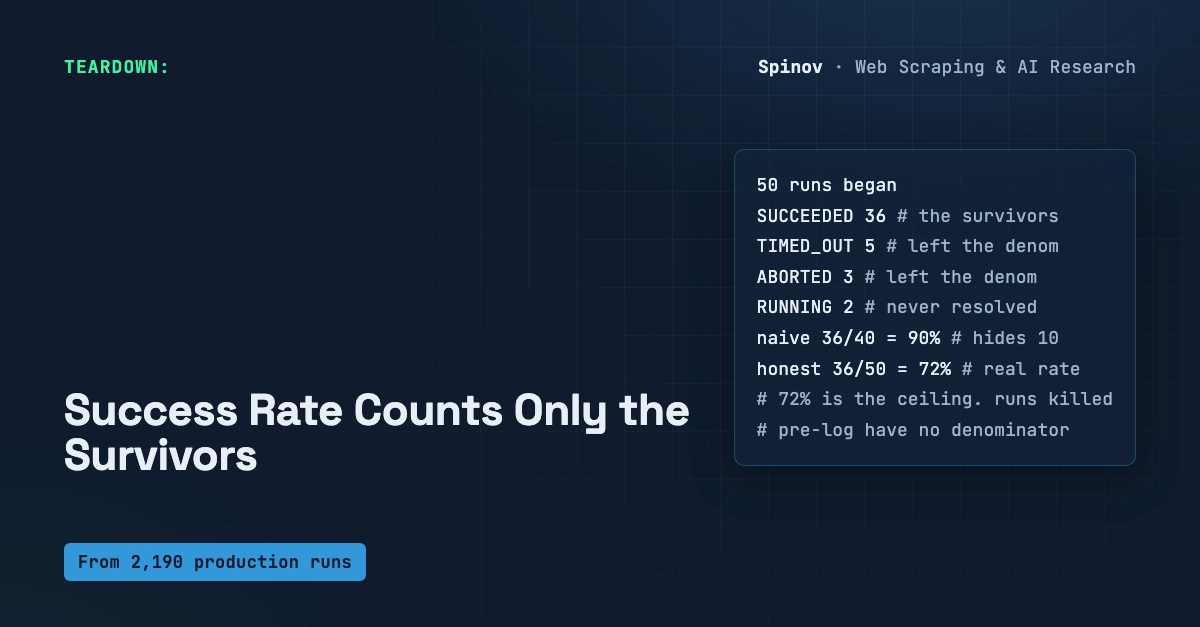
Recompute the agent scorecard from its primary event journal before you trust it: a self-reported metric is the actor grading itself. scorecard_reconcile.py re-derives every metric independently and flags divergence. On the divergent fixture a claimed 58% win-rate sits over zero closed trades, yielding 5 DIVERGENT and 1 UNSUPPORTED metric and exit 1, blocking the add-capital decision.
AI disclosure: I wrote scorecard_reconcile.py with an AI assistant and ran it myself, offline, before publishing. Every number in the output blocks below is pasted from a real local run on Python 3.13.5, stdlib only, on the synthetic fixtures included in this post. I checked the exit codes, hashed the STDOUT twice to confirm it is byte-for-byte deterministic, and edited every line. The external figures (the SEC's $12.3M case) are the SEC's numbers, not mine, and I link the primary source. I label which numbers are theirs and which are mine.
In short:
A self-reported metric and a real one look identical on a dashboard. The agent prints both.
scorecard_reconcile.py reads the scorecard the agent claimed plus the journal of events it logged, then recomputes each metric from the journal and flags anything that does not reconcile.