At some point in most of our production AI projects, someone looks at the monthly API bill and asks whether we can do something about it. The answer is always yes — but the specific answers vary a lot depending on what you are actually spending the money on.
This post covers the techniques that moved the needle for us, in rough order of impact. Some of these are obvious in retrospect. A few took longer than they should have to figure out.
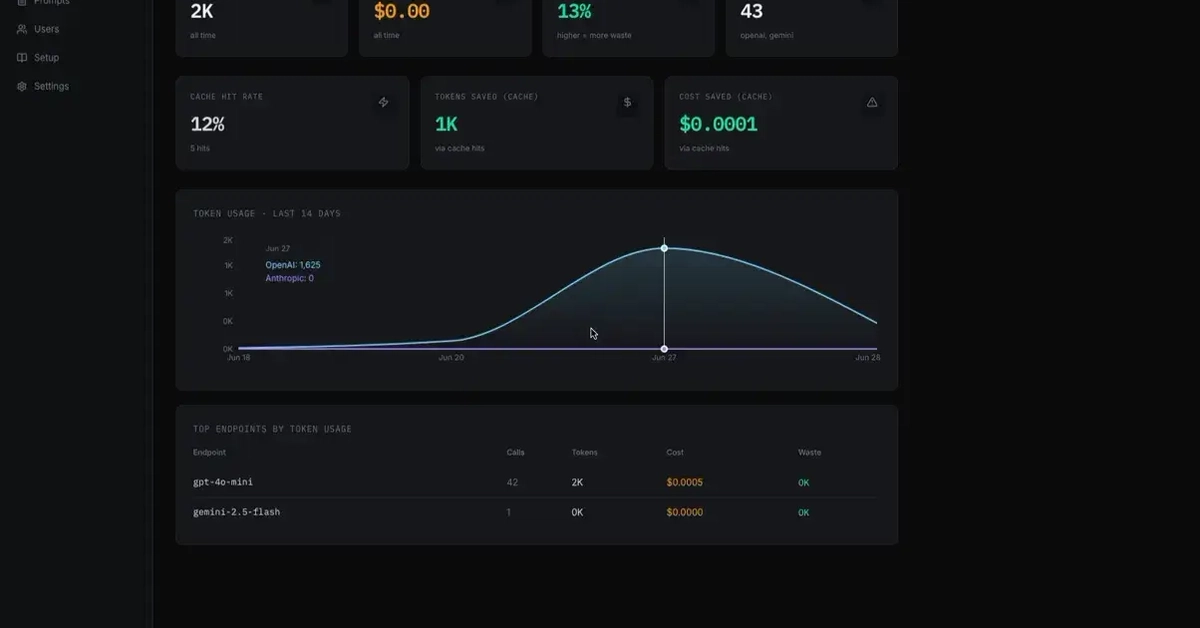
Where the money actually goes
Before optimising anything, you need to know what is driving your costs. LLM API pricing is based on tokens — input tokens and output tokens, usually priced differently, with output tokens costing more.
In most production systems we have built, the cost breakdown looks something like this: a large fraction of input tokens are repetitive context — the same system prompt, the same retrieved documents, the same few-shot examples — sent with every request. Output tokens are often smaller than people expect, because most real-world tasks involve classification, extraction, or short-form generation rather than long prose.