Here is something I did not realize about the Model Context Protocol until my context window kept feeling full for no reason.
Every MCP server you connect loads its full set of tool definitions into the context window on every single request. Those schemas are not free. Each tool costs a few hundred tokens, and they are sent before the model reads a word of your prompt.
Five typical servers, with a dozen or more tools each, commonly add up to 50,000 to 75,000 tokens of overhead per request. That is real money on every call, and latency you feel on every turn. It also crowds out the context you actually want the model to use.
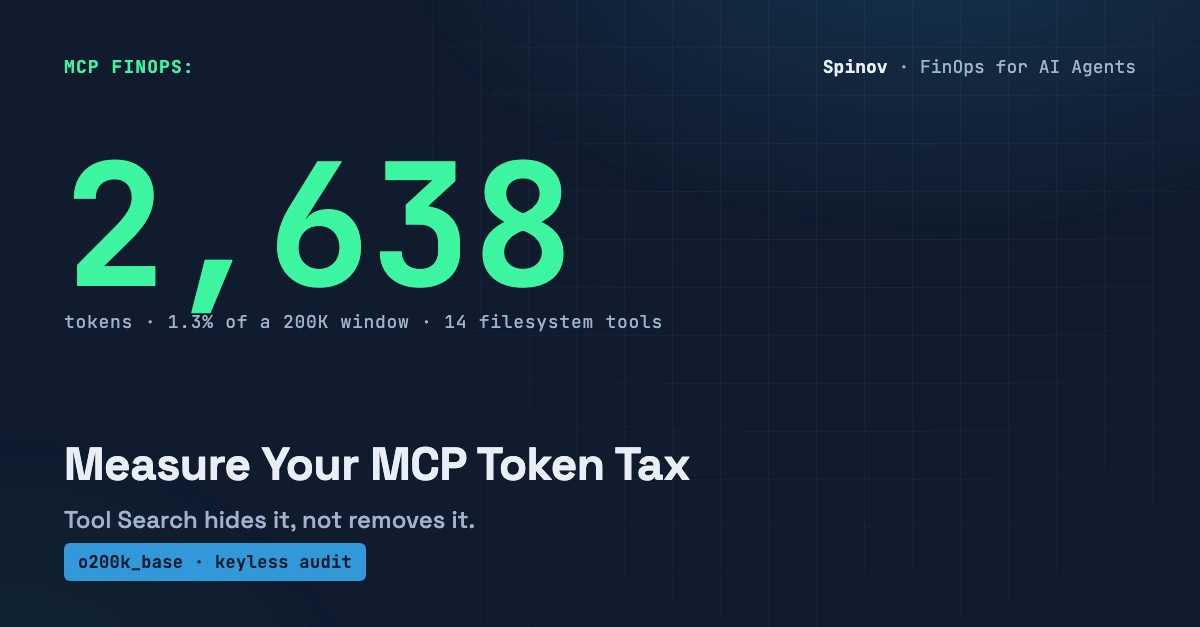
Measure it first
You cannot cut what you cannot see. A rough rule is about 200 tokens per tool plus a small per-server overhead. I built a tiny tool that prints an estimate for your real config (and checks security while it is at it):