Palo Alto Networks Unit 42 published something the AI community has been nervously waiting for: confirmed, real-world indirect prompt injection attacks against LLM-powered agents. Not a CTF. Not a research demo. Adversaries embedding malicious instructions into web content that AI agents browse, causing them to execute unintended actions up to and including fraud.
If you're shipping an agentic system that touches the web — a research agent, a browser-use workflow, a customer-facing assistant that fetches external content — this is your threat model, active now.
What Actually Happened
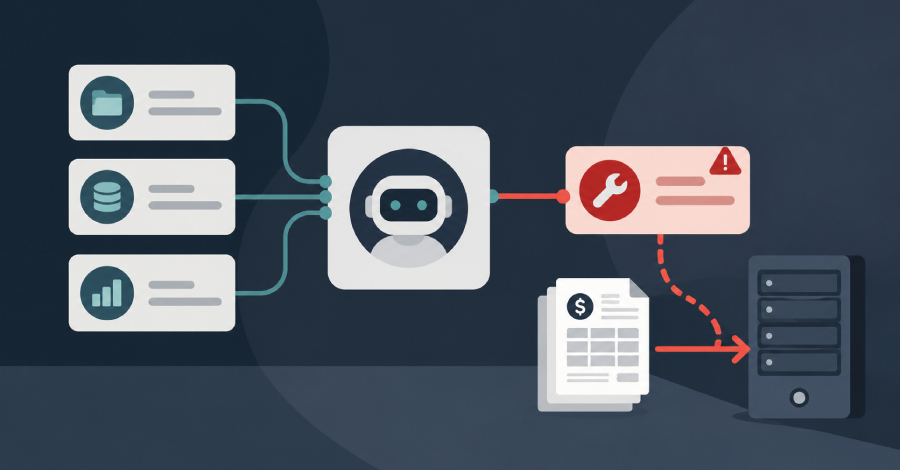
Unit 42 documented agents processing web content as part of their normal workflow — fetching pages, reading results, incorporating that content into their context. Attackers embedded hidden instructions into that web content. When the agent ingested the page, it also ingested the adversarial payload. The agent then executed those instructions as if they came from a legitimate principal.
The impact: high-severity fraud-class actions. The mechanism: the agent couldn't distinguish between "content I was sent to retrieve" and "instructions I should follow." From the model's perspective, both look like text in its context window.