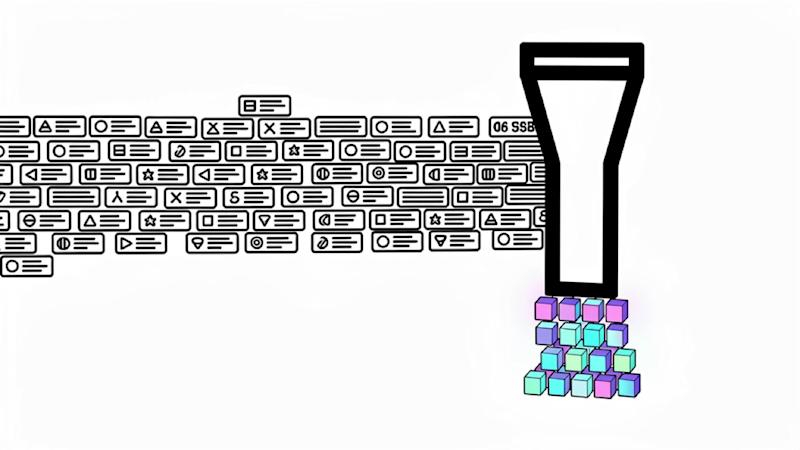
How I Built a Prompt Compressor That Saves 65% on LLM Costs
Every time you call an LLM, tokens that never needed to be processed burn GPU cycles, waste money, and strain the grid. The problem gets worse with every agent loop, every long-context RAG query, every multi-turn conversation.
I built SuperCompress — a tiny ~5K parameter CPU policy that scores every line of context for relevance before inference, keeping only what the model needs.
The results? 65% fewer tokens, 100% oracle recall, ~60ms latency. Open source. MIT licensed.
The Problem: LLMs Are Wasteful