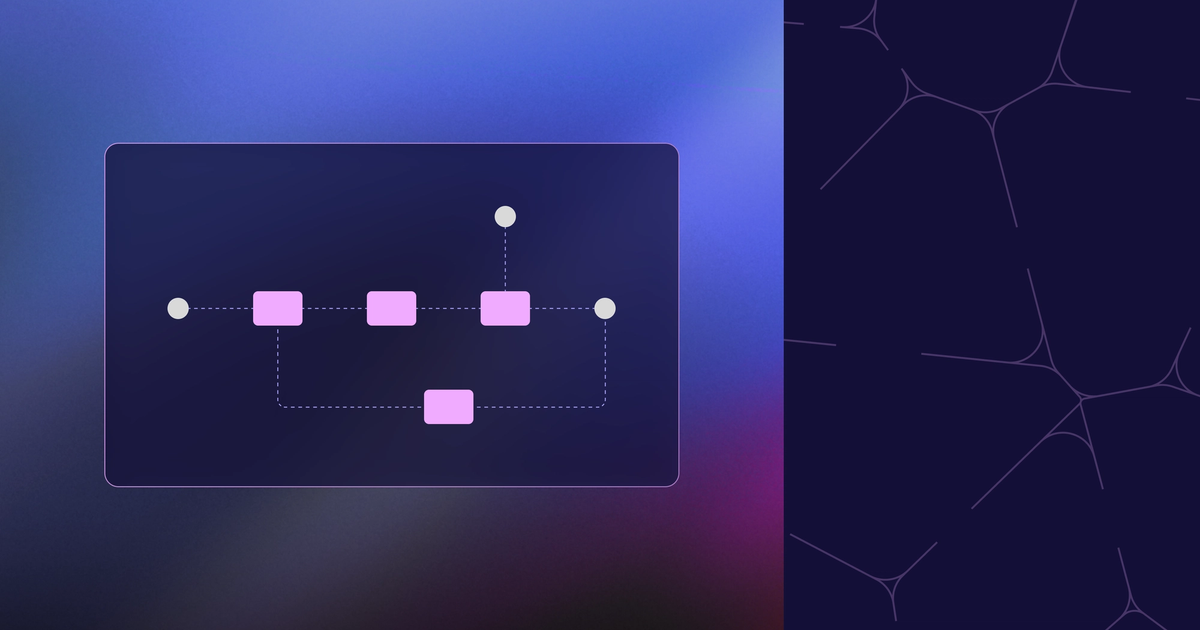
You maintain a fork. Upstream moves. You sync, things break, you fix them, you verify, you ship. A few weeks later, upstream moves again. The cycle repeats.This post describes a general method for automating that cycle using AI coding agents. We apply it to our fork of vLLM, walking through a concrete case where a routine upstream release silently broke Cohere's cohere-transcribe-03-2026 ASR model on our fork, with the fix flowing back upstream as a vLLM PR.In practice, this approach has compressed the time to absorb a new upstream release from weeks to days, with humans only reviewing the outcome. The skills powering this workflow are open-sourced at cohere-ai/vllm-skills.The problemMaintaining a long-lived fork of an actively developed project is a recurring cost. But upstream releases also carry features, performance improvements, and bug fixes that you want. Staying in sync is not just maintenance, it's how the fork keeps getting better. The problem is that every upstream release also introduces a disturbance: merge conflicts, changed APIs, removed functions, new dependencies, or broken tests. The fork maintainer's job is to absorb that disturbance and restore a working state.The structure of this work is always the same:Sync the new upstream version into the fork.Measure by running tests, benchmarks, evals to see what broke.Fix conflicts, adapt to API changes, update tests.Repeat steps 2 to 3 until everything passes.Ship the updated fork.This is a feedback loop. It already exists in every team that maintains a fork; it's just slow and manual. For our vLLM fork, absorbing a typical upstream release used to take weeks of intermittent developer attention, and the goal of the work described below is to bring that down to days of mostly unattended agent time.Feedback systemsIn control theory, a closed-loop system continuously compares its output to a reference and adjusts to close the gap. But real systems also face disturbances: external inputs that push the system away from its desired state.r(t) is the reference, the desired value that the system should produce.y(t) is the output, the actual value that the system produces.e(t) is the error, the gap between reference and measurement, computed as r(t) − measured_output.d(t) is a disturbance, an external force acting on the system that pushes the output away from the reference.The controller uses the error to adjust the system; the feedback brings output closer to the target. A well-designed feedback loop doesn't just track the reference; it rejects disturbances by detecting their effect on the output and driving the error back toward zero without manual intervention.Cruise control is the textbook example. You set a desired speed (reference), the car maintains it (system), but a hill or headwind appears (disturbance). A good controller notices the speed drop and adjusts throttle automatically.Fork maintenance has exactly the same structure.r(t), referenceCustom changes working correctly on the latest upstreamd(t), disturbanceNew upstream release: conflicts, API changes, breaking changesControllerResolve conflicts, update patches, fix testsSystemThe fork itself (code, tests, CI)y(t), outputRuntime behavior of the fork after syncingMeasurementTest suite, benchmarks, evalsThe goal is to automate the entire loop — sync, measure, fix, repeat — so we can absorb upstream improvements with minimal human intervention.Our pre-agent processThere are several ways to sync a fork with upstream: merge, cherry-pick, and rebase are the most common. Merge preserves both histories, but produces a tangled commit graph that makes it hard to tell custom changes from upstream. Cherry-pick gives precise control, but doesn't scale when upstream moves hundreds of commits per release; you end up maintaining a growing list of picks that drifts out of sync. Rebase replays your custom commits on top of the new upstream tag, producing a clean, linear history where your patches sit clearly on top. The tradeoff is that rebase rewrites history and forces a force-push, but for a fork with a small number of custom commits on top of a fast-moving upstream, the clarity is worth it.At Cohere, we settled on rebase early on. Before the agent-based workflow described below, our pipeline already mixed scripted automation with manual work.Rebase: A GitHub Actions workflow attempts the rebase onto a target upstream tag, replaying previously-seen conflict resolutions from a shared git rerere cache.Resolve conflicts: When the workflow's automated rebase fails, a developer picks up locally, resolves the remaining conflicts by hand (often with an LLM assistant), verifies CI, and uploads the updated rerere cache.Verify and ship: Once CI is green on the rebased branch, it becomes the new base for the fork.This process already combines several kinds of automation: git rerere replays known resolutions, GitHub Actions runs the rebase attempt and CI, and LLMs assist with individual coding and debugging tasks. But the human is still part of the controller, stitching the pieces together, choosing which fixes to apply, and deciding when to re-run. The feedback loop works; it just turns slowly. The agent-based workflow described below keeps the same structure, but lets an agent play the controller role, so iterations happen at machine speed and humans only intervene at the edges.Automating each componentThis method decomposes the loop into three, agent-automatable components. Each maps to a piece of the control diagram.1. Disturbance injectionAn agent skill detects and applies new upstream releases. It rebases the fork onto the new tag and resolves merge conflicts automatically. This is the disturbance entering the system: a deliberate, automated action that we know will temporarily break things, but that we want to absorb as quickly as possible.The skill needs to:Detect which upstream tag the fork is currently based onCheck whether a newer tag existsPerform git rebase --onto with the fork's custom commitsResolve conflicts (using upstream diff context to make informed decisions)2. Measurement collectionAfter a rebase, the fork is in an unknown state. Measurement tells you how far you are from the goal: a working fork with all custom behavior intact. Without it, the agent is flying blind.The measurements themselves (tests, benchmarks, evals) are defined by the project and already exist before any automation. What the agent automates is collecting them: a test-runner skill that knows how to set up the environment, execute the verification suite, and report results.Tests: Unit, integration, and correctness testsBenchmarks: Performance checks (throughput, latency, resource usage)Evals: Domain-specific quality metrics (accuracy, perplexity, task scores)The output is the error signal: which tests fail, which benchmarks regress, which evals degrade. The richer and more reliable the measurements, the faster the controller can converge. A fork with a thin test suite gives a weak signal; the agent won't know what's broken or how close it is to done.3. ControllerAn agent skill closes the loop. After the rebase lands and measurement results come back, the skill:Reads test and benchmark resultsIdentifies failures and regressionsApplies fixes (resolve build errors, update broken tests, adapt to API changes)Re-runs measurementRepeats until all measurements pass, or escalates to a humanThis is the controller driving the error to zero. The key insight is that the agent doesn't need to get the rebase right on the first try, it just needs to iterate — exactly like a developer would.Case study: vLLMvLLM is an open-source LLM serving engine. At Cohere, we use it across the inference stack, from RL rollouts and evals during model development to serving user requests in production. We maintain a fork to carry custom commits — additional model support, custom kernels and optimizations, modified entrypoints, extra tests — some of which are in the process of being upstreamed, others specific to our needs. The challenge is replaying those commits onto each new upstream release without breaking anything. Upstream cuts a release roughly every few weeks, and each one is substantial: the diff between tags often touches hundreds of files.The skill stackWe built five skills, open-sourced at cohere-ai/vllm-skills, that instantiate the general pattern. Each skill is a markdown document that a coding agent reads and executes interactively, with access to the terminal, file system, and the tools it needs.install-vllmEnvironment setupCreates a uv virtualenv, installs vLLM in editable mode with the correct precompiled CUDA wheellocal-test-runnerMeasurementRuns Buildkite CI-equivalent tests locally on NVIDIA GPUs; parses .buildkite/test_areas/*.yaml, manages HuggingFace tokens, captures logsdetect-upstream-baseDisturbance detectionFinds the upstream tag (v1) the fork is currently based on via git merge-base + git describerebase-assistantControllerRebases custom commits from v1 onto v2, resolves conflicts using upstream diffs for context, verifies the result with test-runnerHow a rebase runsThroughout this section: v1 / v2 are the old and new upstream tags, and b1 / b2 are the fork branches before and after the rebase.A typical invocation: "/auto-rebase sync the current branch with the latest upstream release and make sure <test> passes."auto-rebase checks prerequisites (gh auth status), then invokes detect-upstream-base to find v1 (e.g., v0.19.0).It fetches upstream tags and discovers v2 (v0.19.1). It presents the release to the user and waits for confirmation.It collects verification checks from the user (e.g., pytest tests/entrypoints/openai/correctness/test_transcription_api_correctness.py).It invokes rebase-assistant, which:Analyzes the custom commits on b1 (git log v1..HEAD)Verifies that tests pass on b1 first (using local-test-runner with the v1 wheel), which is the gate that ensures we have a known-good baselineBacks up b1, creates b2, optionally squashes custom commitsRuns git rebase --onto upstream/v0.19.1 <fork-point> HEADResolves conflicts by comparing upstream/v1..upstream/v2 diffs to understand what changedRuns tests on b2 (using local-test-runner with the v2 wheel)If tests fail: inspects failures, compares against the v1 baseline, applies fixes, and re-runs (the inner feedback loop)Once all checks pass, auto-rebase presents a summary (commits replayed, conflicts resolved, test results) and offers to push.As a sequence of skill interactions:The inner loop is the controller iterating on b2: local-test-runner reports a failure, rebase-assistant applies a fix and re-runs until the tests pass.Worked example: Cohere Transcribe on v0.19.1Here is a real invocation of this loop, end to end.Setup: Our fork sits at cohere-transcribe-v0.19.0, one custom commit on top of upstream v0.19.0 that enables a correctness test for Cohere's cohere-transcribe-03-2026 ASR model. vLLM added support for this model architecture in v0.19.0, but the upstream test was commented out because the weights weren't published yet. Our custom commit just un-comments one line. # TODO (ekagra): turn on after asr release
Automating fork maintenance with AI agents | Cohere
AI agents automate vLLM fork maintenance, cutting upstream sync time from weeks to days by auto-rebasing, testing, and fixing conflicts.
2,234 words~10 min read