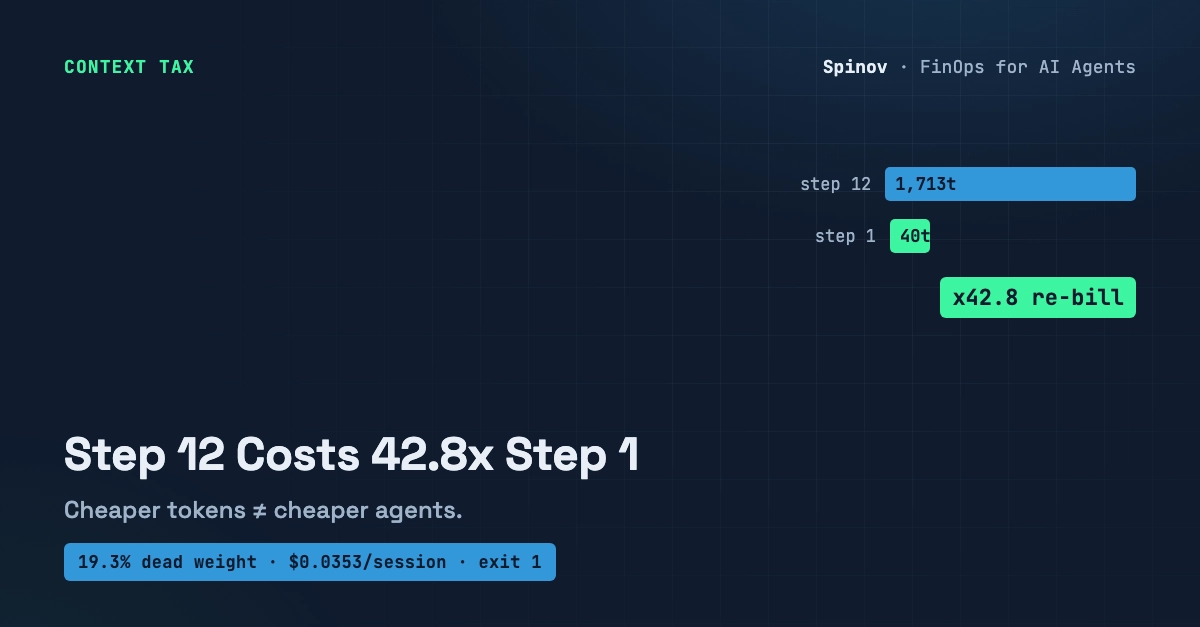
Here's the number that made me rethink everything I thought I knew about agent architecture: most models today use only 50 to 65% of their available context window — even when given a million tokens.
That means your "$0.99 for a million tokens" deal is actually closer to "$1.50 to $2.00 per million useful tokens." And if you're running MCP servers in your agent loop? Add another 10 to 32x multiplier on top. You're not buying efficiency. You're buying a very expensive space heater.
I ran the numbers on this for three weeks across four production agent pipelines. Here's what I found, what surprised me, and what I'm doing differently now.
The Context Utilization Problem
Benchmark scores have always felt suspicious to me. A model scores 92% on a million-token benchmark — but that benchmark is designed to use a full million tokens. Production usage is a different animal.