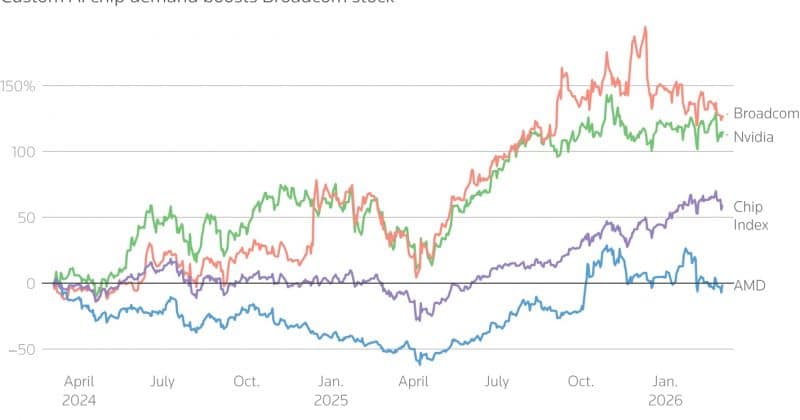
Photo credit: openai.comOpenAI and Broadcom unveiled Jalapeño on 24 June 2026, the company's first custom-built inference chip, designed from a blank sheet in nine months and pitched by Broadcom chief executive Hock Tan as about half the cost of running AI on standard GPUs. Every headline since has reached for the obvious story: a strike at Nvidia. That story is true and partial. Jalapeño is two announcements stacked on top of each other. The first is a piece of silicon. The second, the one that carries more weight, is OpenAI's move to own the most expensive line on its books — the cost of answering you, each time you press enter.What OpenAI actually put on the tableJalapeño is an application-specific integrated circuit — an ASIC, in the trade — which means it does one narrow job at low cost. That job is inference: the work a trained model performs every time it writes a line of code, answers a question, or runs an agent. OpenAI designed the chip around its own understanding of how large language models behave, then handed manufacturing to TSMC and the silicon implementation, networking and production scale-up to Broadcom, with Celestica building the boards and racks. Tan and Broadcom president Charlie Kawwas delivered the first physical sample to Sam Altman and Greg Brockman this week.The company calls it an "Intelligence Processor", the first in what OpenAI and Broadcom describe as a multi-generation compute platform. Engineering samples are running in OpenAI's labs at production target frequency and power, including a workload built on its GPT-5.3-Codex-Spark model. OpenAI says early testing shows performance per watt well ahead of the best chips on the market today, with the detailed numbers due in a technical report some months out. Brockman said the early readings looked strong.Jalapeno at a glanceDetailChipOpenAI's first custom AI acceleratorTypeASIC, built for LLM inferenceDesign and partnersOpenAI (design); Broadcom (silicon implementation, Tomahawk networking); Celestica (boards, racks, systems)ManufacturingTSMC, on a 3nm process (per reporting)Build timeNine months, design to tape-outIn the labRunning GPT-5.3-Codex-Spark at production frequency and powerClaimed gainsPerformance per watt well ahead of current chips (OpenAI); about 50 per cent cheaper than GPUs (Hock Tan)DeploymentFirst systems by end 2026; next generation around 2028Inference is the bill that keeps runningTraining a model is a one-time, brutal expense — months of computation to build the thing. Inference is what follows, and it runs for the life of the product. Every prompt from every user spends a little compute, and OpenAI now serves hundreds of millions of them. As the user base climbs, inference becomes the cost centre that swallows the rest.The figures explain the urgency. OpenAI's inference costs reached about $8.4 billion in 2025 and are projected to climb past $14 billion in 2026, on one much-quoted estimate. The company's gross margin slid from 40 per cent in 2024 to 33 per cent in 2025 as serving costs quadrupled. For the full year 2025, OpenAI booked $13.07 billion in revenue against $34 billion in spending, an operating loss close to $21 billion. Jalapeño is a margin play before it is anything else.From scratch, in nine monthsHere is the part that made semiconductor engineers sit up. Most high-performance chips take years to move from design to tape-out, the point at which a design is frozen and sent to the foundry. OpenAI and Broadcom did it in nine months — what OpenAI believes to be the fastest such cycle in advanced silicon, a claim worth treating with care until the industry weighs in.The speed came from a particular kind of cooking. Rather than take a general-purpose accelerator and adapt it — reheating a dish built for someone else's menu — OpenAI started with raw ingredients: its own kernels, memory patterns and serving systems, the things it knows because it runs them across ChatGPT and the API every day. A chip built from scratch around one menu can be tuned to it in a way a reheated one resists.There is a recursive twist. OpenAI used its own models to speed up parts of the design and optimisation — the same intelligence it sells to users now helping to build the chips that will serve future users. Richard Ho, who leads OpenAI's hardware programme and worked on Google's early TPU effort before joining, said the team tuned the architecture around the kernels, memory movement, networking and serving patterns that matter most to frontier models. His 40-strong group did the design; Broadcom turned it into something a foundry could produce at scale.The 50 per cent questionThe number everyone repeated came from Tan, who told reporters that early samples show savings of about 50 per cent against typical AI GPUs. Treat it with the caution any vendor figure deserves. OpenAI plans to publish the supporting benchmarks in a technical report some months out, and "cost" folds together silicon price, power and utilisation in ways one percentage hides. Still, the direction reads clear, and even a slice of that saving, spread across a fleet that burns billions in compute, rewrites the arithmetic of the business.The architecture aims at utilisation as much as raw speed. OpenAI says Jalapeño reduces data movement and balances compute, memory and networking so that real-world performance lands closer to the chip's theoretical ceiling — the gap most accelerators leave on the table when they run live traffic rather than benchmarks. A chip that wastes fewer cycles on a known workload is worth more to OpenAI than a faster one that idles.The full-stack betOpenAI's own argument for Jalapeño is a full-stack one. It already builds the models, the products on top of them, and the data centres that run them. Designing the chip pulls the last layer in-house — chip, kernels, memory, networking, scheduling, the model and the product all answering to one owner. When every layer optimises for the same goal, the company argues, each prompt gets faster and cheaper than it would on hardware built for everyone. "By designing more of the stack ourselves, we can serve more intelligence with greater efficiency," Brockman said. It is the playbook Apple has run for years with its own chips, and the one Google, Amazon and Meta now run inside their data centres.Why this is really a Broadcom storyStrip away the OpenAI logo and a quieter winner stands in the room. Broadcom has spent the AI boom turning itself from a networking-silicon company into the workshop where the giants get their custom chips made. Google's TPUs, Meta's accelerators, and now OpenAI's Jalapeño share that workshop. Tan told CNBC that demand from his custom-chip customers is "simply insatiable", and that it runs hot through 2027 and into 2028. Broadcom adds that OpenAI and Anthropic alone are consuming compute faster than it expected.The market read it the way you would expect. Broadcom shares ticked up about 2 per cent on the reveal, having jumped as much as 9 to 11 per cent when the original partnership surfaced in October 2025; the stock has multiplied close to sevenfold since the end of 2022. Bernstein kept its Outperform rating and a $550 price target, and 44 of 48 analysts tracked rate the stock a buy. Nvidia, for its part, dipped about a quarter of a per cent — the market's verdict that Jalapeño is a warning shot rather than a wound.A strike at Nvidia, with the knife held looselyHere the Formula 1 reading helps. For three years OpenAI has raced as a customer team — buying its engines from Nvidia, the constructor everyone leases from, and running on whatever the supplier hands over. Jalapeño is OpenAI building its own power unit. The catch: it has built that engine for one part of the circuit only. Inference is the race it enters; training, the brutal model-building phase, stays on Nvidia's hardware.The partnership with Nvidia also runs deep. In February 2026 Nvidia put a reported $30 billion into OpenAI and signed it up for 10 gigawatts of its next-generation Vera Rubin platform, the bulk of it for training. OpenAI keeps Nvidia in the fast lane where the heaviest compute lives. What Jalapeño changes is the pit strategy: the most repetitive, highest-volume work — serving you a Codex answer — moves to a chip OpenAI tuned itself.That is the deeper threat to Nvidia, and it has more to do with structure than with any single benchmark. Once Google, Amazon, Microsoft, Meta and OpenAI all run serious custom-silicon programmes, the question every finance chief starts asking is why each inference dollar should flow through one general-purpose architecture. Nvidia's pricing power rests on that default. Jalapeño chips away at it.Everyone is building their own silicon nowOpenAI joins a club that has been meeting for years. Google has run Tensor Processing Units since the last decade. Amazon has Trainium and Inferentia, which it rents to AWS customers. Microsoft — OpenAI's largest backer and cloud host — shipped its Maia 200 inference chip in January 2026 on the same TSMC 3nm process, and reporting says it already powers OpenAI's GPT-5.2 models inside Azure. Meta runs its MTIA line. The off-the-shelf era, where everyone queued for Nvidia, is giving way to one where the largest operators design around their own workloads.Who else builds their own AI chipsCustom chipBuilt forOpenAIJalapeñoLLM inferenceGoogleTPUTraining and inferenceAmazonTrainium / InferentiaTraining / inference, rented via AWSMicrosoftMaia 200Inference; powers OpenAI models in AzureMetaMTIAInference, recommendation and generative AIThe race runs wider still. AMD is selling its Instinct MI450 GPUs into the same data centres; Cerebras is pushing its wafer-scale design; ByteDance opened talks with Qualcomm in June to build its own data-centre ASICs; Alibaba's T-Head and Huawei have unveiled inference parts of their own. Custom silicon has become the price of admission for anyone running AI at national scale.What Jalapeno means for IndiaFor Indian readers, the chip lands closer to home than it looks. India is OpenAI's second-largest user base, and ChatGPT usage in the country quadrupled over the past year, led by students and developers. That growth sits on an awkward truth: serving a cheap user in Delhi costs OpenAI about the same as serving a paying one in San Francisco. Cheaper inference is the lever that makes a price-sensitive market pay.Look at the $5-a-month ChatGPT Go plan OpenAI built for India — among the cheapest it sells anywhere. A plan at that price works only if the cost of each answer keeps falling, and a chip tuned to halve inference cost is the kind of thing that keeps a $5 tier alive. The same logic flows to every Indian developer building on OpenAI's API: cheaper inference upstream tends to reach them as cheaper tokens downstream, which is the difference between a margin and a loss for an Indian startup serving its own users.The hardware story has an India chapter of its own. OpenAI is in talks to build a data centre of about a gigawatt in the country under its Stargate programme — which would rank among India's largest — in part to satisfy the data-localisation demands of the Digital Personal Data Protection Act. Add the IndiaAI Mission's $1.2 billion of state backing, the OpenAI Academy India programme, a New Delhi entity and Altman's courting of the government, and Jalapeño becomes one more piece of a sovereignty pitch: AI served to Indians, on infrastructure that touches Indian soil, at a cost the market can bear. Google and Reliance already pitch their builds the same way. OpenAI wants its own chip in that argument.What to watch nextThe formation lap is over; the real race starts when the numbers land. Three things will tell us whether Jalapeño matters as much as the launch suggested. First, the technical report — the moment Tan's 50 per cent claim meets independent scrutiny. Second, the deployment ramp: OpenAI wants the first systems live by the end of 2026, and Tan has signalled that his earlier figure of 1.3 gigawatts for next year could prove low. Third, whether OpenAI extends its own silicon from inference into training — the day it does, Nvidia's grip on the heavy compute loosens too.Strip everything else away and the contest runs deeper than Jalapeño versus the H100. It is whether the people who write the largest cheques in computing keep routing every inference dollar through one company's chips, or start building their own roads. OpenAI just laid its first stretch of tarmac. The grid is forming.end of article
Broadcomm’s Jalapeno Chip Could Make ChatGPT Cheaper To Run, And Cheaper In India
OpenAI and Broadcom unveiled Jalapeño on 24 June 2026, the company's first custom-built inference chip, designed from a blank sheet in nine months and pitched by Broadcom chief executive Hock Tan as about half the cost of running AI on standard GPUs. Every headline since has reached for the obvious story: a strike at Nvidia. That story is true and partial. Jalapeño is two announcements stacked on top of each other. The first is a piece of silicon. The second, the one that carries more weight, is OpenAI's move to own the most expensive line on its books — the cost of answering you, each time you press enter.
2,052 words~9 min read