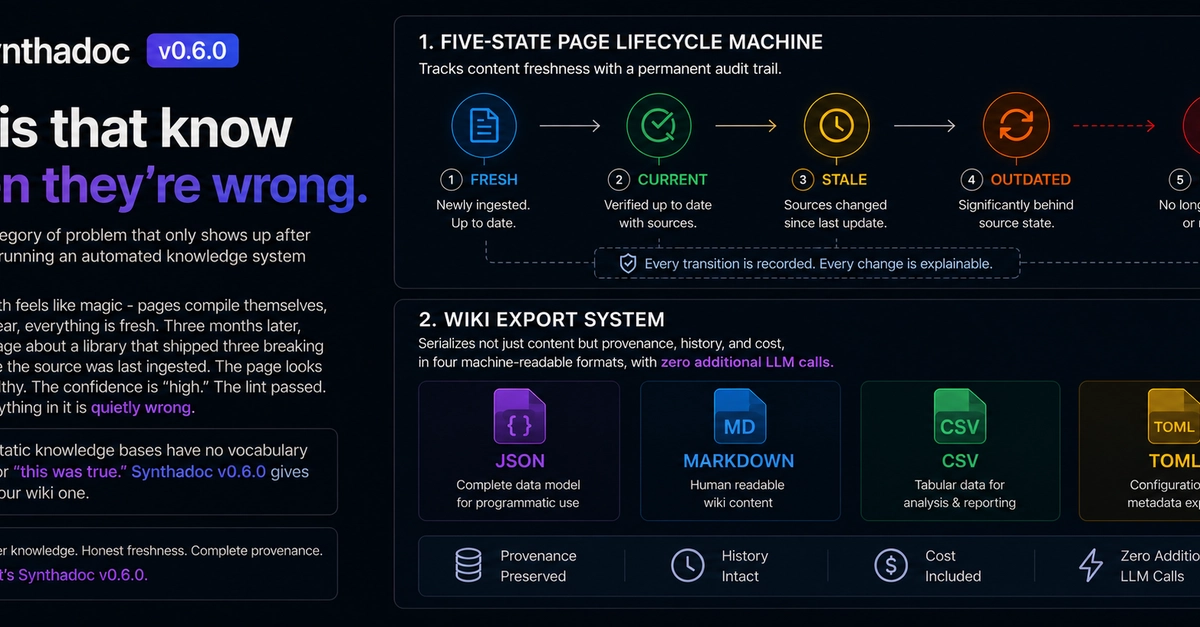
I've spent the last several months building ANIMUS, an autonomous system in Rust that gives a local LLM persistent memory. The idea is simple: a knowledge graph that grows on its own, cycle after cycle, as the system reads documents, detects gaps in its knowledge, and fills them in.
For months, the metric I watched most closely was the node count of the graph. It kept climbing. I felt good about that.
Until I ran a full audit and found out that 52% of those nodes were undetected duplicates. Of 1,892 reported nodes, only 911 were actually unique.
How did this happen?
ANIMUS's autonomous loop actively looks for "gaps" — holes in its knowledge that the system decides to fill on its own. The problem: an overly aggressive filter was excluding certain categories from the gap pool, which trapped the system in a loop of re-exploring the same ~40 topics for thousands of cycles. Each pass generated content that was similar but not identical to the last — different enough to avoid triggering any exact-duplicate check, but substantially the same information rephrased.