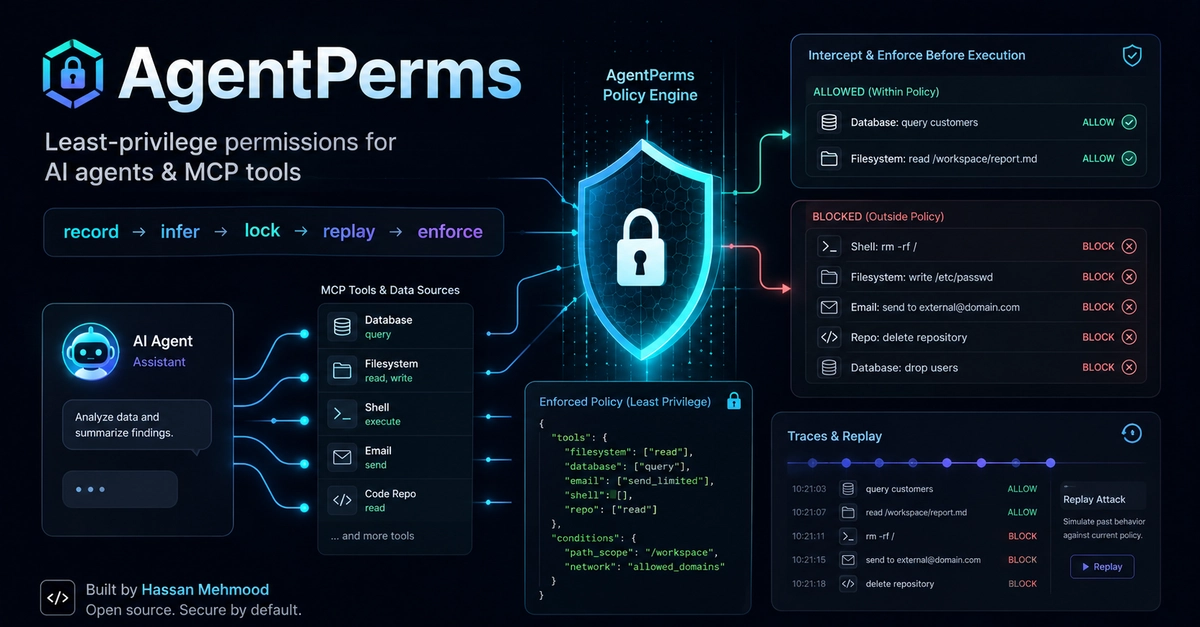
A few months ago I gave an autonomous agent write access to a real database. It was a LangChain-style loop — plan, call a tool, observe, repeat and one of the tools ran SQL.
It worked great in the demo. Then I watched it, during a "clean up the test rows" task, generate this:
sql
DROP TABLE users;
It didn't run (staging, and I was watching). But the lesson landed: the LLM doesn't know the difference between a destructive command and a safe one until it's already calling the tool. And by then your code is one cursor.execute() away from an incident.