This article was originally published on GetYourDozAi.
Key Takeaways
MiniMax M3 — the first open-weight model to combine frontier coding, a 1M-token context window, and native multimodal input (text + image + video).
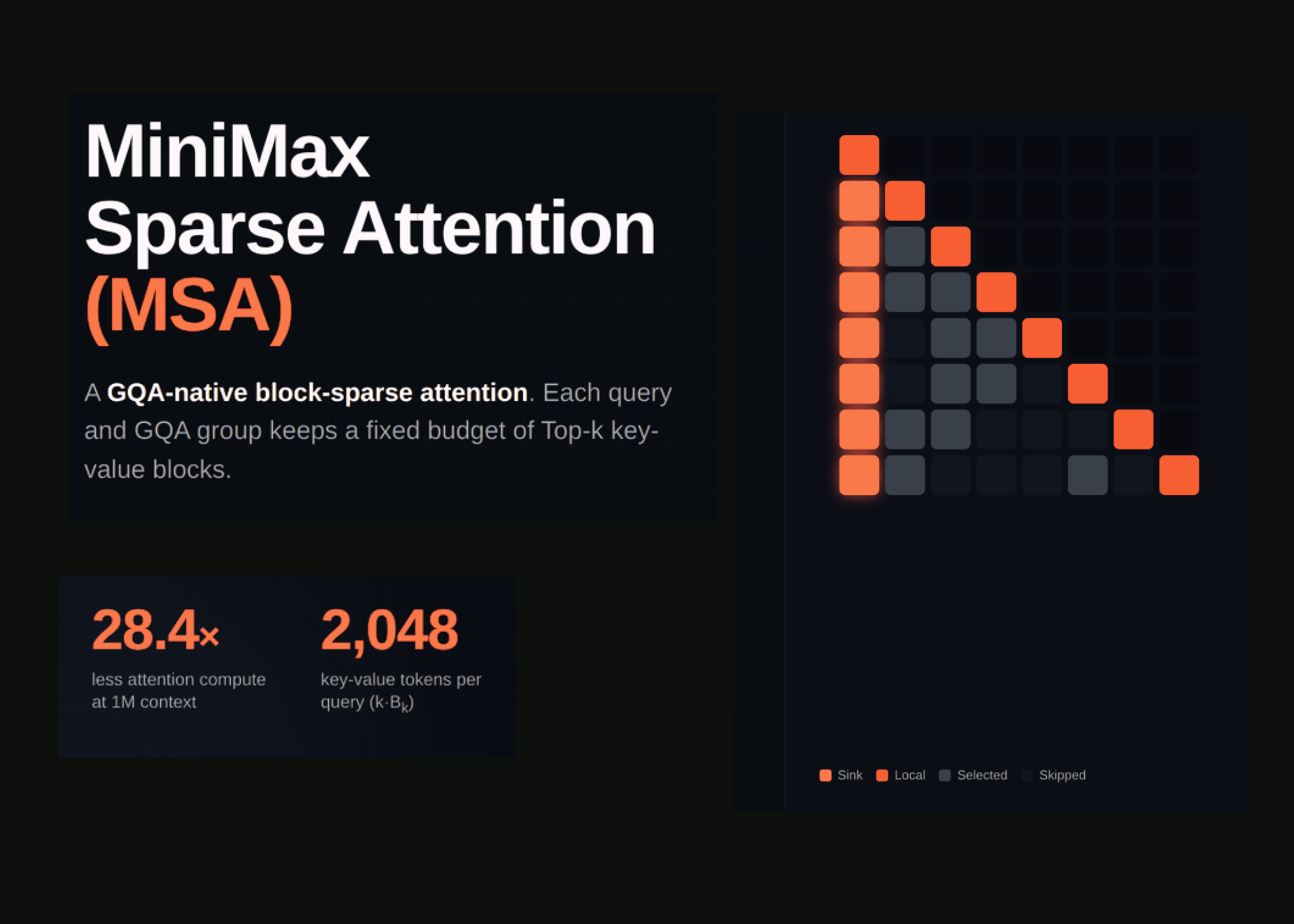
MiniMax Sparse Attention (MSA) — a novel mechanism that reduces compute by 28.4x at 1M context by attending only to the 2,048 most relevant tokens per query, backed by a peer-reviewed arXiv paper.
Priced at 5-10% of rivals — $0.30/M input tokens (promo) vs $5.00 for Opus 4.8 and GPT-5.5, making it the best dollar-for-dollar coding model available through an API today.