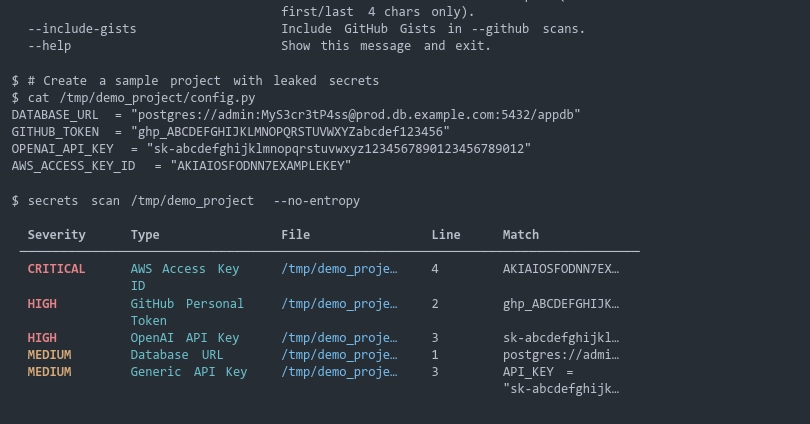
I build a small open-source tool (rojaprove) that checks whether an AI app leaks its hidden instructions. This week I spent time finding where it fails, on purpose, so I can tell you the boundary honestly instead of letting a green checkmark imply more than it should.
Here's the short version, and then the detail.
How it works (plain language)
You plant a "canary" — a secret string that should never show up in normal output. Think of it like a marked bill: you write down the serial number, and if that exact number ever turns up somewhere it shouldn't, you know it leaked. The tool sends attack-style prompts to your app, then checks the responses for that exact string. If the canary appears, that's a leak. If not, it passes.
The strength: it's a plain text match, so the verdict is certain and repeatable. No AI guessing whether something "looks risky." The string is there, or it isn't.