Feature flag migrations have a reputation problem. Ask anybody who’s been through one before and you’ll hear the stories, usually from someone still a little frustrated about a bad cutover, with a postmortem or two to show for it.
The reputation is mostly undeserved. While the risks are real, they’re well understood and easily controlled. Getting a migration right doesn’t require a big coordinated effort. It requires knowing what can go wrong and designing around it from the start.
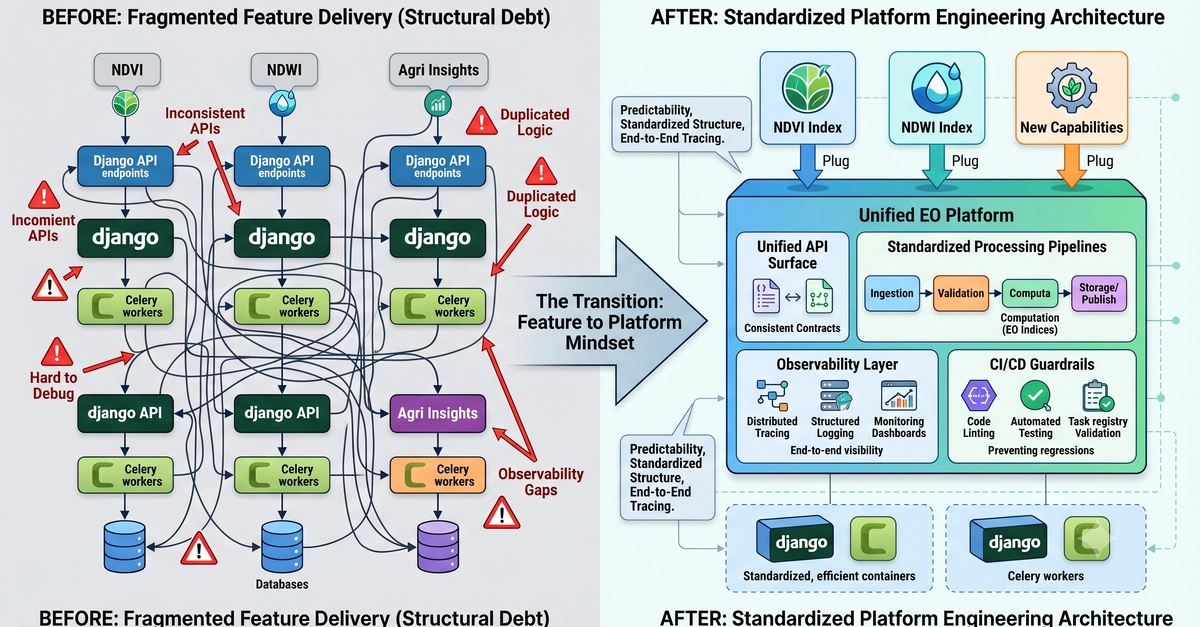
Why feature flag migrations stall
In a large organization, a legacy SDK can span thousands of call sites across dozens of microservices. Replacing something like oldClient.variation with newClient.evaluate is repetitive work, but with agentic developer tooling, it can be done in days rather than weeks.
The harder problems are about risk, not effort. Production safety is the real concern and it comes down to three specific technical challenges: