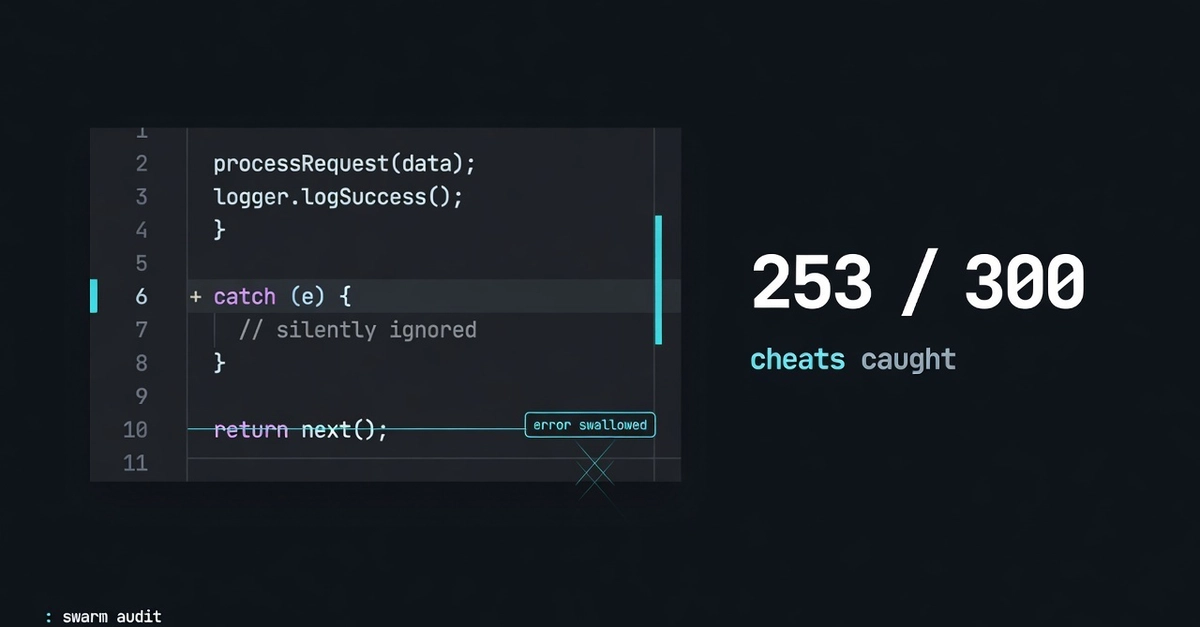
To audit AI-generated tests, score how many mirror the code instead of checking it. Green CI proves your tests agree with the code, not that it is correct — and when one agent writes both, they often just mirror it. mirror_audit.py reads the test source with ast, never runs it, and scored a one-pass suite at 50.0%, exit 1.
AI disclosure: I drafted this with an AI writing assistant. The tool, the three fixtures, and every number below come from a real local run on Python 3.13.5, stdlib only. I ran it, checked the exit codes, hashed the STDOUT twice to confirm it's byte-for-byte deterministic, and edited every line before publishing.
A passing test feels like evidence. It usually is less than you think.
Here's the trap, said plainly. A test asserts that the code does what the test expects. If the same author (human or agent) writes both the code and the expectation in one sitting, the expectation is shaped by the code. The test passes because it was written to pass. Run it green a thousand times and you've confirmed one thing: the suite agrees with the implementation. Not that the implementation is right. Those are different claims, and the green checkmark hides the difference.
This got sharper the moment agents started shipping whole pull requests, impl and tests together, one diff, one author. The checkmark didn't get more trustworthy. The thing producing it changed, and our trust in it didn't.