As a backend engineer who has spent more than a decade designing distributed systems, asynchronous microservices, and fault-tolerant architectures, my first encounter with Generative AI development felt slightly unsettling. In traditional software design, determinism is the gold standard. We pass an explicit parameter to a service, validate inputs against a rigid API schema, handle database transactions, and expect a highly predictable output.
Generative AI flips this paradigm. Large Language Models (LLMs) are fundamentally non-deterministic, probabilistically driven text prediction engines.
If you view an LLM simply as an "AI magic box," your production applications will break. However, if you treat an LLM as a highly volatile, stateful, and non-deterministic third-party external API with unique payload constraints, you can engineer reliable backend systems around it.
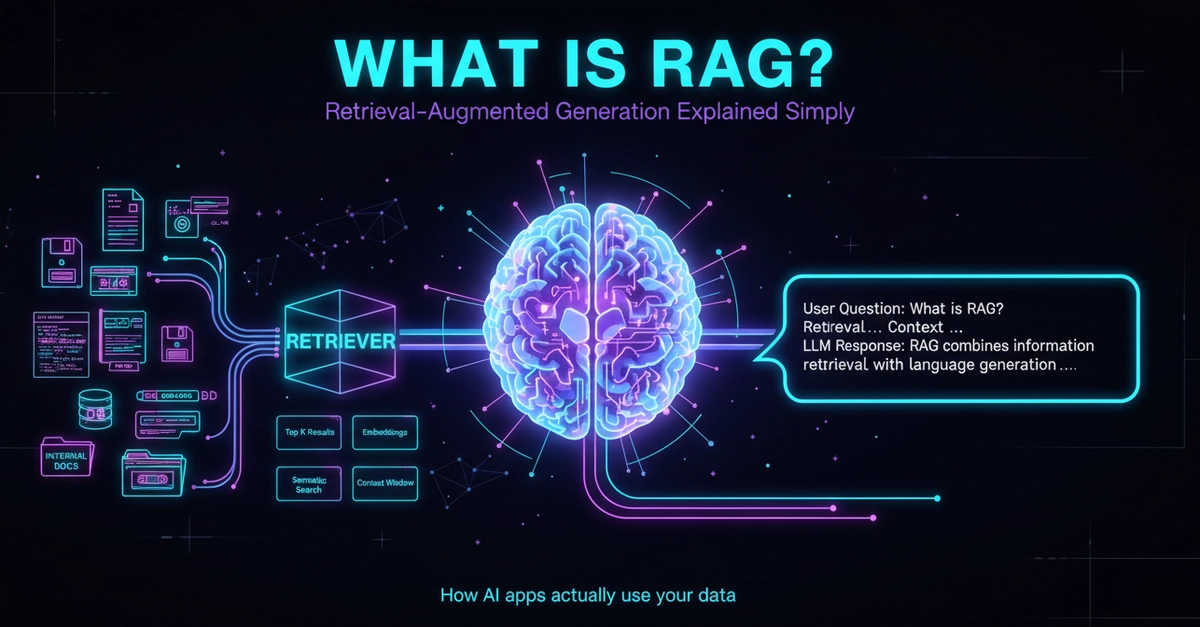
This article explores the foundational GenAI stack—LLMs, Retrieval-Augmented Generation (RAG), and structured prompting—through the lens of an enterprise systems architect.
1. The Foundation: LLMs as Volatile External APIs