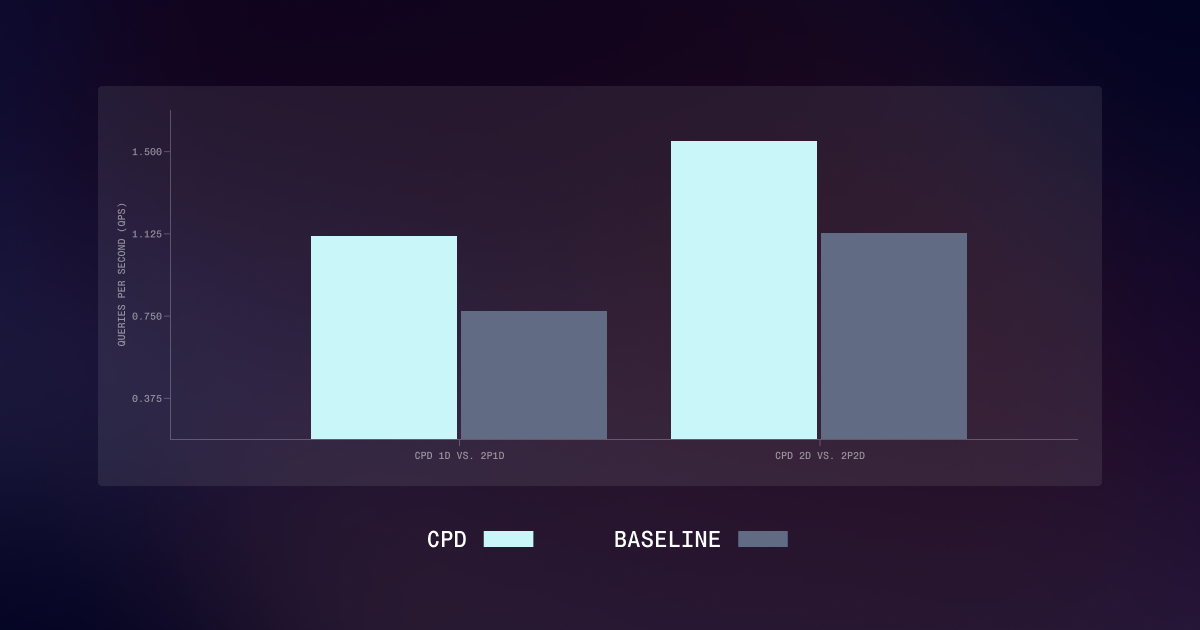
What: AMD shipped ATOM + ATOMesh, a ROCm-native LLM serving stack whose headline trick is prefill/decode disaggregation — splitting the two phases of inference onto separate pools of GPUs instead of crowding them onto one.
Why: Prefill and decode have opposite bottlenecks — prefill is compute-bound, decode is memory-bandwidth-bound — so running them on the same worker wastes hardware and lets one long prompt stall everyone else's token stream.
vs prior: A co-located server (vanilla single-pool vLLM) interleaves prefill and decode on the same GPUs; disaggregation runs each on its own pool tuned for its bottleneck, paying for it by shipping the KV cache across the interconnect between them.
Think of it as
A restaurant kitchen that splits the prep station from the plating line.