One day I had the AI keep building out a feature, and partway through something felt off: replies got slower, it started rambling, it re-asked things I'd already told it, and with the work clearly unfinished it told me "all done, you can take a break now."
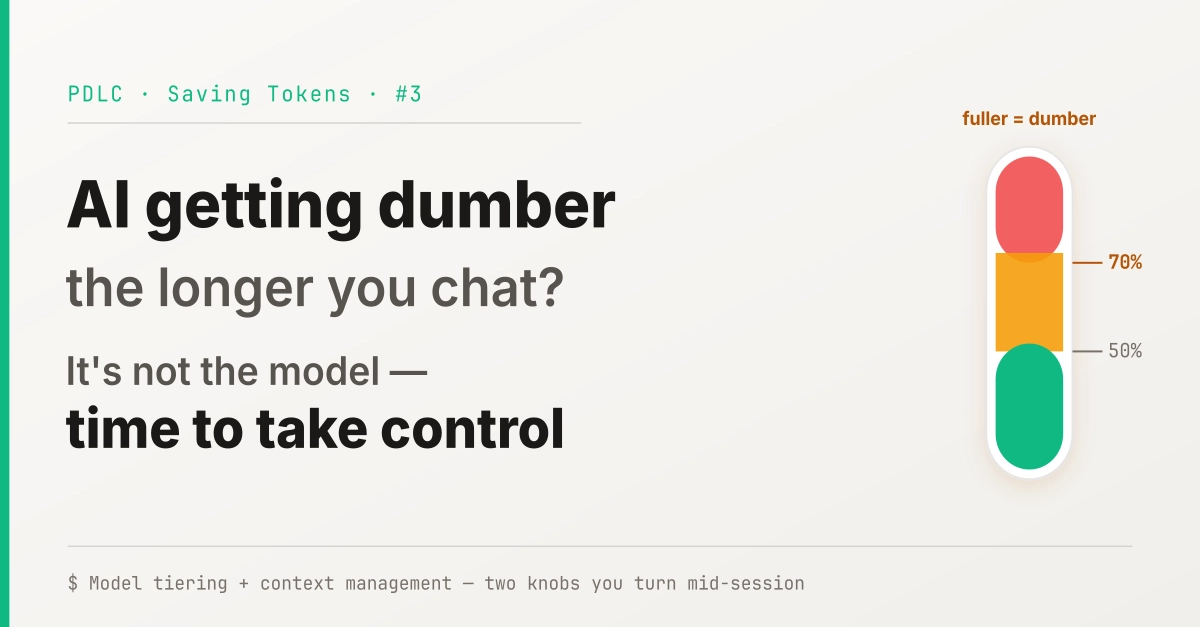
At first I figured the model was just having an off day. Then I looked at the context—it had crept past 80%. I'd been so busy pushing forward I forgot to clear it. Cleared it, asked again, and instantly it was sharp again: fast and on point.
That's when I started taking this seriously. The last two posts were all about squeezing the volume down before things hit the context—that's pre-work. This one is about two things you do after you start, mid-session—they decide how many tokens the same work costs, how fast it runs, how stable it stays.
There are actually two knobs in one conversation
There are two knobs you can turn mid-session, pointing in different directions.






