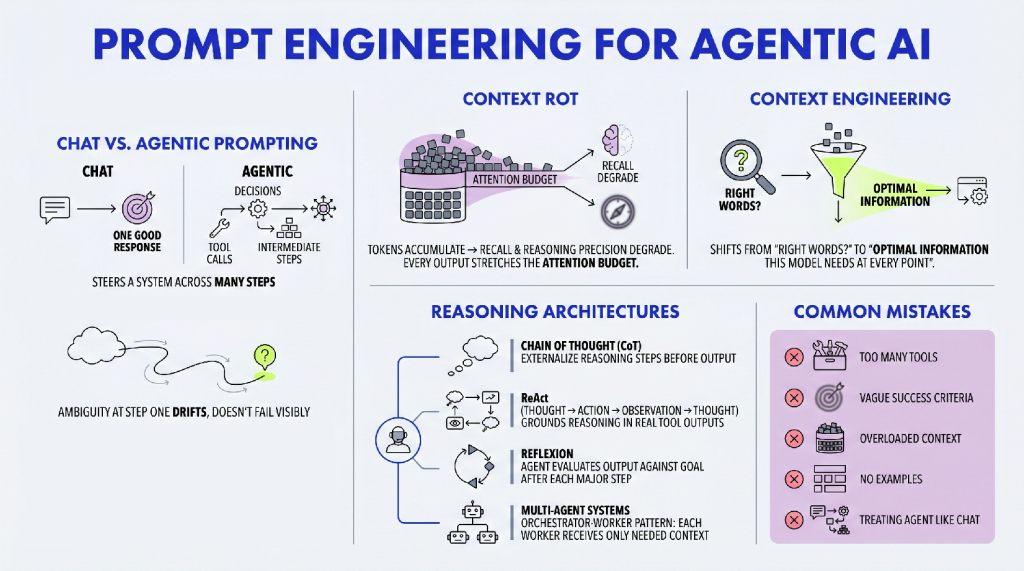
Most agent stacks have matured in roughly the same direction: we version the code, test the tools, constrain the runtime, and instrument the loop. But one part of the system still often lives as an unversioned artifact copied between docs, chats, and notebooks: the prompt.
That mismatch gets harder to ignore once you start treating the agent harness as the real product. If the harness is what determines reliability, cost, safety, and task success, it is strange that the prompt is often the least engineered part of the stack.
That question led me to build SynthAgent: a small framework that generates a task-specific prompt, tool plan, and runtime strategy at task time instead of relying on one fixed prompt and one fixed loop for every task.
This post is best read as an architecture exploration, not a benchmark report. I have not yet run the A/B test that would justify a strong performance claim over a fixed-prompt baseline. What I do have is a working harness, a clear design thesis, and a set of implementation lessons that were useful enough to write down.
I’ll walk through the architecture, show what the synthesized artifacts actually look like, explain the tradeoffs behind the design, and point out where the current version is still weak.