Developers and founders today face a paradox: systems are more complex than ever, yet the expectation for "five-nines" availability remains non-negotiable. Traditional DevOps practices--manual triage, static thresholding, and ticket shuffling--are collapsing under the weight of microservices, serverless architecture, and the rapid integration of Large Language Models (LLMs).
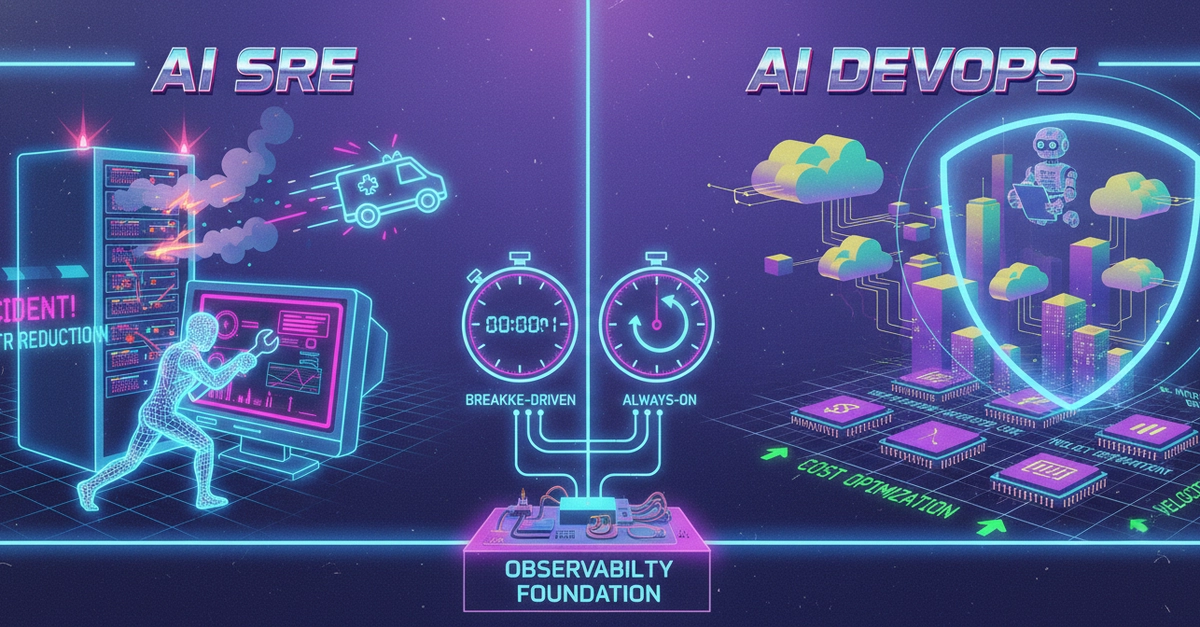
AI Ops (Artificial Intelligence for IT Operations) is not just a buzzword; it is the architectural shift required to survive this complexity. It moves beyond monitoring to active intelligence. This guide breaks down how to build a practical AI Ops stack, reduce Mean Time To Recovery (MTTR) by up to 50%, and automate the drudgery of on-call rotations.
Moving from Reactive to Proactive Observability
The foundation of AI Ops is not the AI itself, but the quality of data feeding it. Traditional monitoring relies on static alarms (e.g., "Alert if CPU > 90%"). This is flawed because 90% CPU might be normal for a batch processing job but catastrophic for an API gateway. AI Ops replaces static thresholds with dynamic baselines using unsupervised learning.
To achieve this, you must transition from basic metrics to traces and structured events. You cannot automate what you cannot contextually understand.