OpenAI researchers propose a method for predicting how often a new AI model will make mistakes after release. It could fill gaps left by standard safety testing.
Before an AI model ships, it goes through safety testing. These tests try to estimate how often the model will later show unwanted behavior, like producing banned content or deceiving users. According to an OpenAI research paper, most of these tests rely on handwritten, synthetic, or deliberately tricky questions.
But these tests only capture a skewed slice of reality. They're designed to probe for weaknesses, not to reflect what real users actually type. On top of that, models often pick up on the fact that they're being tested and behave differently than they would in normal use. Both issues mean test results say little about how a model will actually perform in the wild.
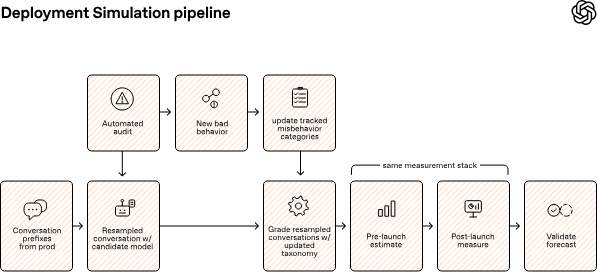
Real conversations instead of synthetic test prompts
Researchers Marcus Williams, Micah Carroll, and their team propose a straightforward approach called "Deployment Simulation." Instead of crafting new test questions, they pull from real, anonymized conversations that users had with a previous model. They keep the conversation history intact, all prior messages, and only have the new, unreleased model rewrite the next response.