I spent the last two weekends building a customer support chatbot for my side project. It was supposed to answer questions from our documentation. The first day was magic – it answered simple questions perfectly. Then came the hard ones.
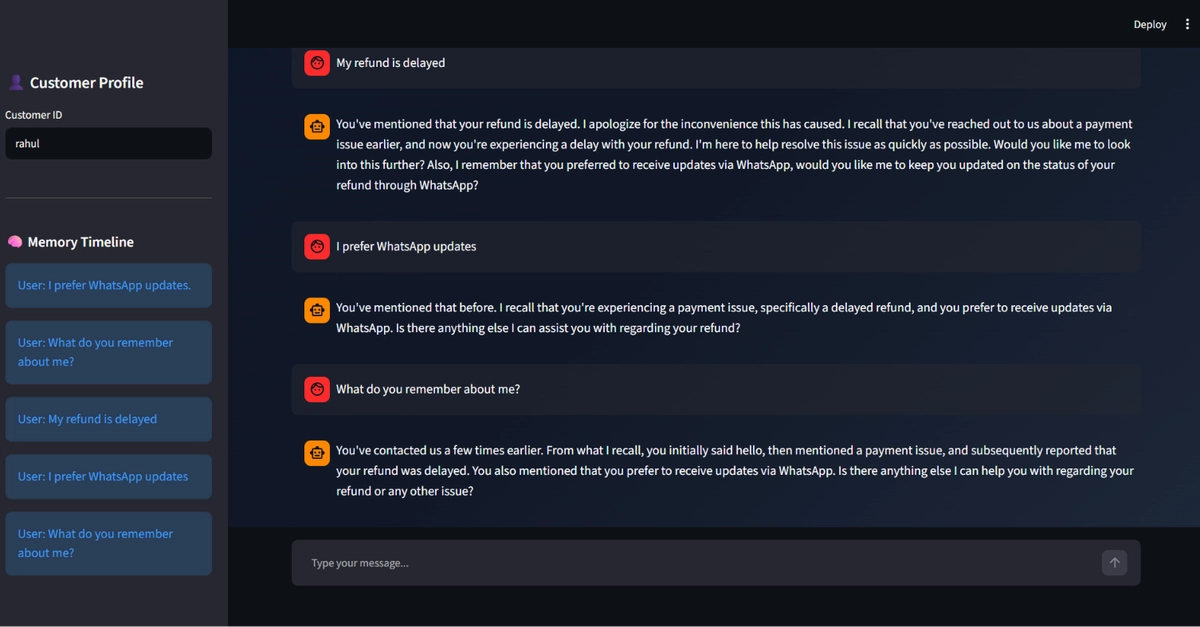
A user asked "How do I reset my password using the recovery email option, because my old method from last year isn't working?" The chatbot replied with a generic link to the password reset page. Completely useless. The problem wasn't the language model – it was that the relevant context was scattered across three different documents, and my naive retrieval setup couldn't connect the dots.
The naive approach that failed
My first attempt was simple: break all documentation into fixed-size chunks (512 tokens), embed them with OpenAI embeddings, and stuff the top-3 chunks into the prompt. This works fine for short, isolated answers. But when a user asks a multi-step question that references prior context ("that old method from last year"), the fixed chunks often lack the necessary background.
I tried a sliding window – overlapping chunks with 50% overlap. That helped a little, but I was still losing information when the relevant data lived in different sections. Worse, as the conversation history grew, the prompt ballooned in size. I was paying for thousands of tokens just to keep the chatbot from saying "I don't know" to the next question.