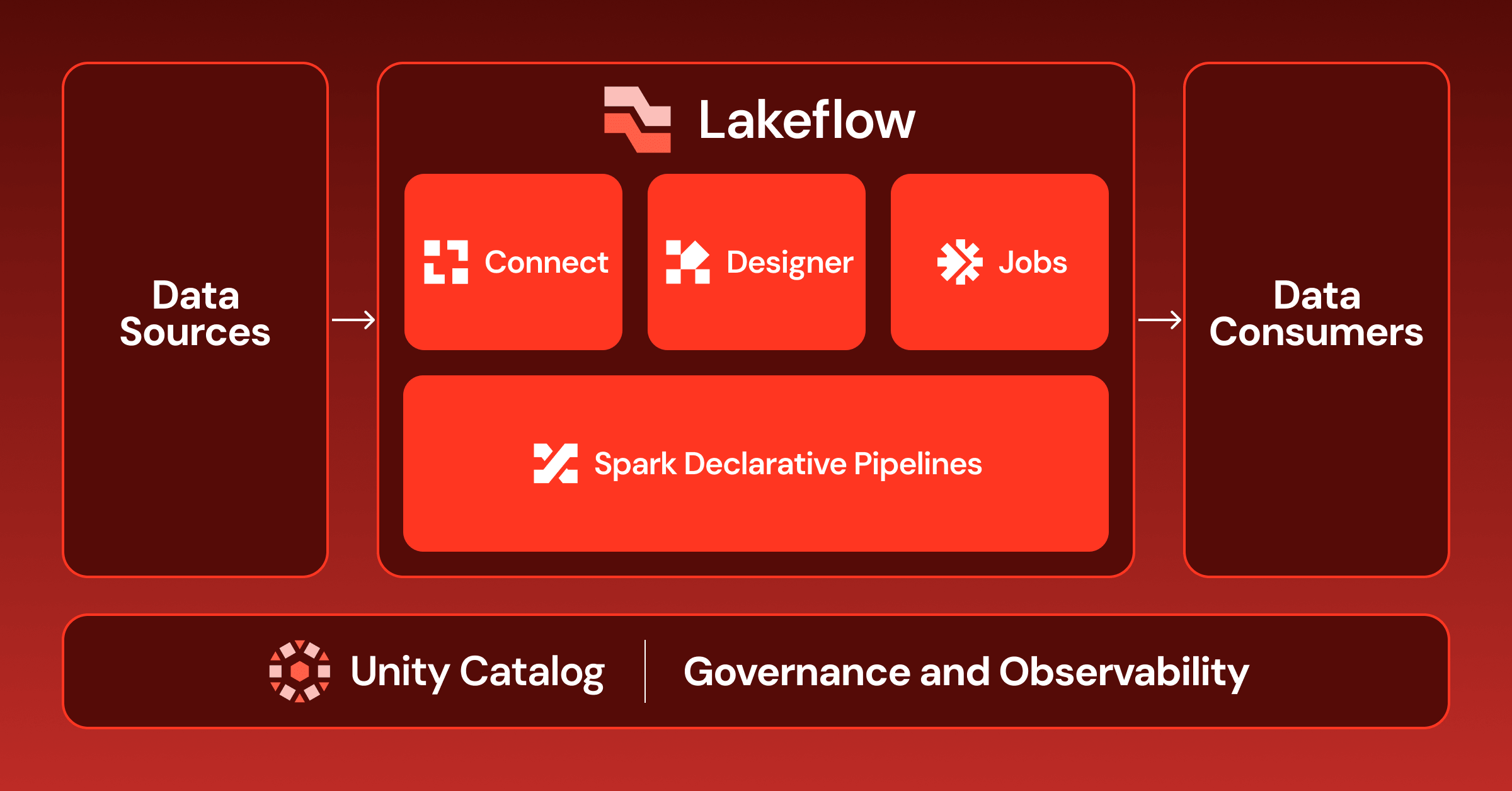
Every organization has data scattered across data warehouses, data lakes, SaaS platforms, cloud drives, and data centers. Data fabrics enable organizations to centralize and control data access, making it easier for users, such as data scientists and citizen data analysts, to find and use trusted and governed data sources.
Data fabrics, data meshes, and distributed data clouds are all platforms to help IT and data teams put some order to the chaos around the myriad of data sources they support. Large companies need data fabrics due to the volume and variety of their data sources.
“A data fabric can be thought of as the connective tissue that ensures consistent accessibility, availability, and understanding of data across an organization,” says Dominic Wellington, data and AI expert at SnapLogic. “Individual siloed platforms may have their own internal data transfer systems, and particular teams or departments may adopt interchanges that work for that domain, but a data fabric operates at a higher level, ensuring that unified data policies are applied end-to-end across the entire enterprise.”
Types of data fabrics
When reviewing data fabrics, it’s important to consider their primary use cases, supported data types, data processing capabilities, data management structures, and governance functions. Below are some considerations when reviewing data fabrics as features, platforms, and stand-alone products.