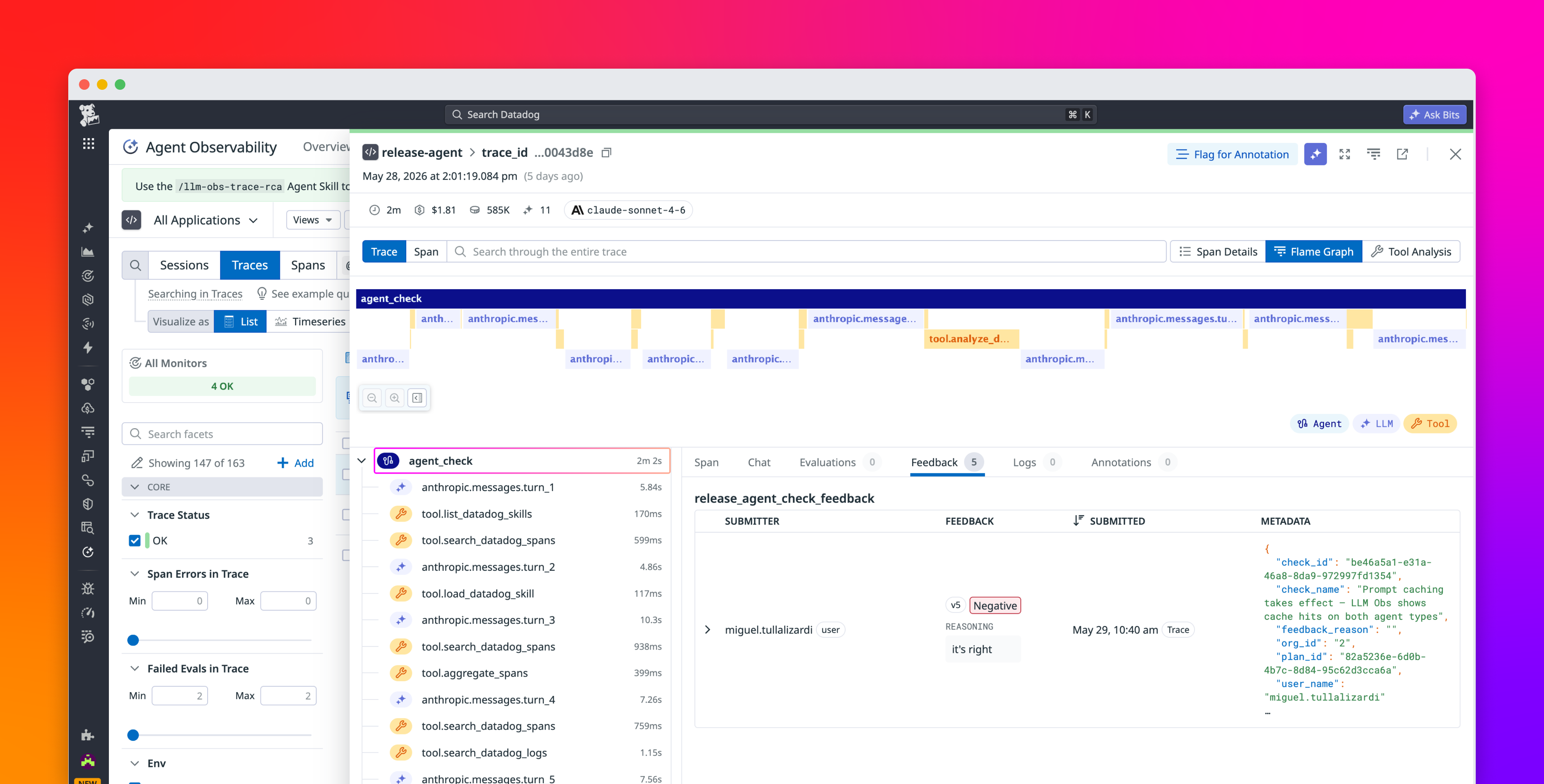
Most teams I talk to have "evals." I ask them where the evals run. The answer is almost always the same: a notebook, a dashboard, a spreadsheet someone updates after a bad week. That is not an eval suite. That is a museum.
Here is the opinion I will defend for the rest of this post: if your agent's quality checks cannot block a merge, they are decorative. The entire value of an eval is that it stops a regression before it reaches a user. A score you read on Monday about a deploy you shipped Friday is a postmortem, not a gate.
We gate code with unit tests. We gate APIs with contract tests. We gate infra with terraform plan. Then we take the single most non-deterministic component in the stack — an LLM agent that can silently change behavior when a vendor ships a new checkpoint — and we let it through on vibes. That asymmetry is the actual bug.
Why "run it locally and eyeball it" rots
The failure isn't that engineers are lazy. It's that manual eval runs degrade under exactly the conditions where you need them most: