LangGraph Fault Tolerance: Building Resilient Agents with Retries, Timeouts, and Error Handlers
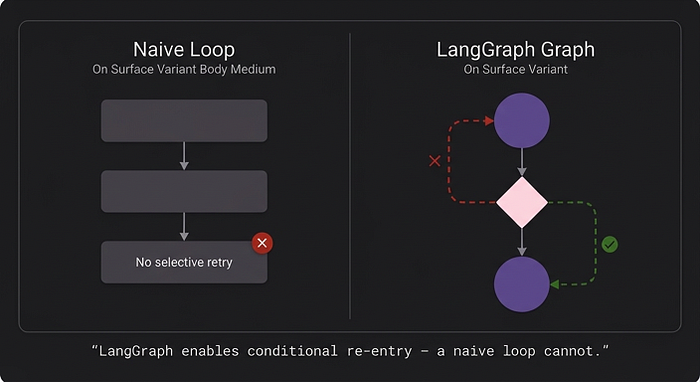
Your agent completed 90% of a complex research task, made fourteen successful API calls, and then hit a transient rate limit on the fifteenth. Now it's dead. Checkpoints won't save you here—they tell you where the agent stopped, not how to recover gracefully. This gap between state persistence and active recovery has been the single largest source of operational burden for teams running production agents, and LangGraph's new fault tolerance primitives finally close it.
The timing matters. As organizations move from proof-of-concept agents to production deployments handling thousands of daily invocations, the economics of manual intervention become untenable. A support agent that requires human restarts 15% of the time isn't a productivity gain—it's a liability. The new @retry decorator, TimeoutPolicy class, and ErrorHandler nodes represent LangGraph's first comprehensive answer to this challenge, building on the framework's existing resilient agent architecture while addressing the operational realities of 2026's agentic workloads.
The Problem: Why Checkpointing Alone Isn't Enough
LangGraph's checkpointing system—whether you're using PostgresSaver, MemorySaver, or the newer distributed options—excels at one job: capturing the complete state of an agent at defined points in execution. When an agent crashes, you can inspect exactly what happened and resume from that state. This is table stakes for any serious agentic system, and LangGraph has done it well.