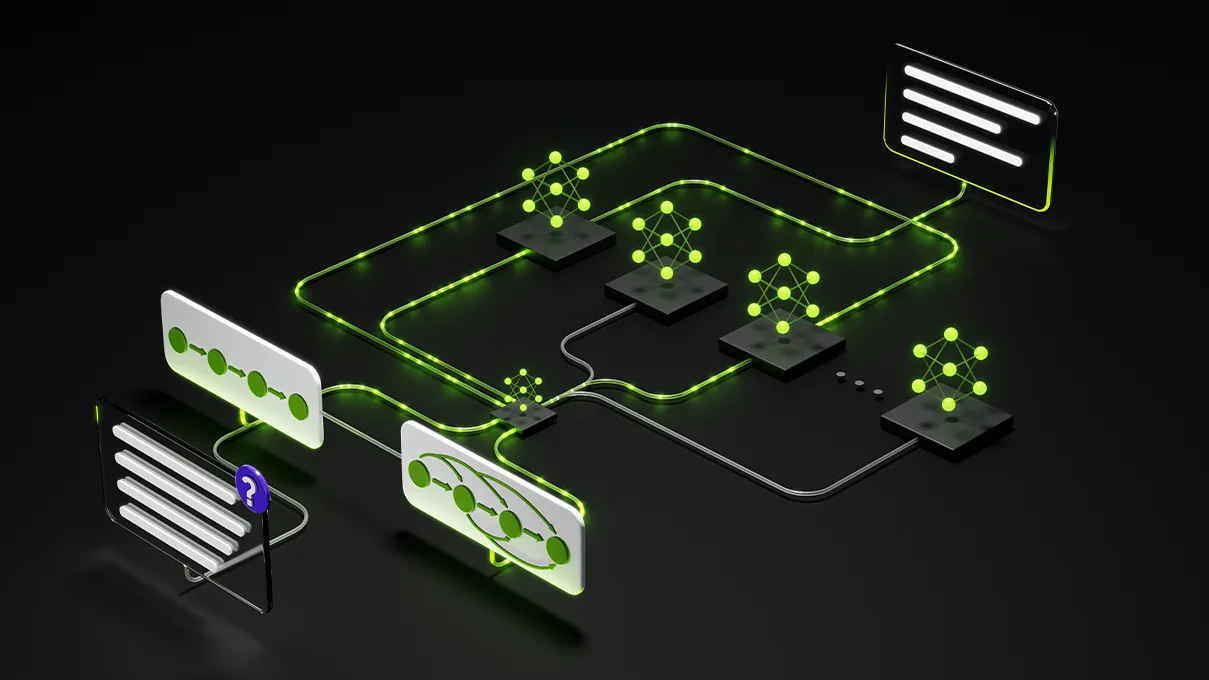
What: The AgentPerf benchmark from Artificial Analysis is the first test built for agentic-AI infrastructure: instead of timing one chat completion, it replays recorded multi-step agent trajectories to see how a serving system holds up under real agent load.
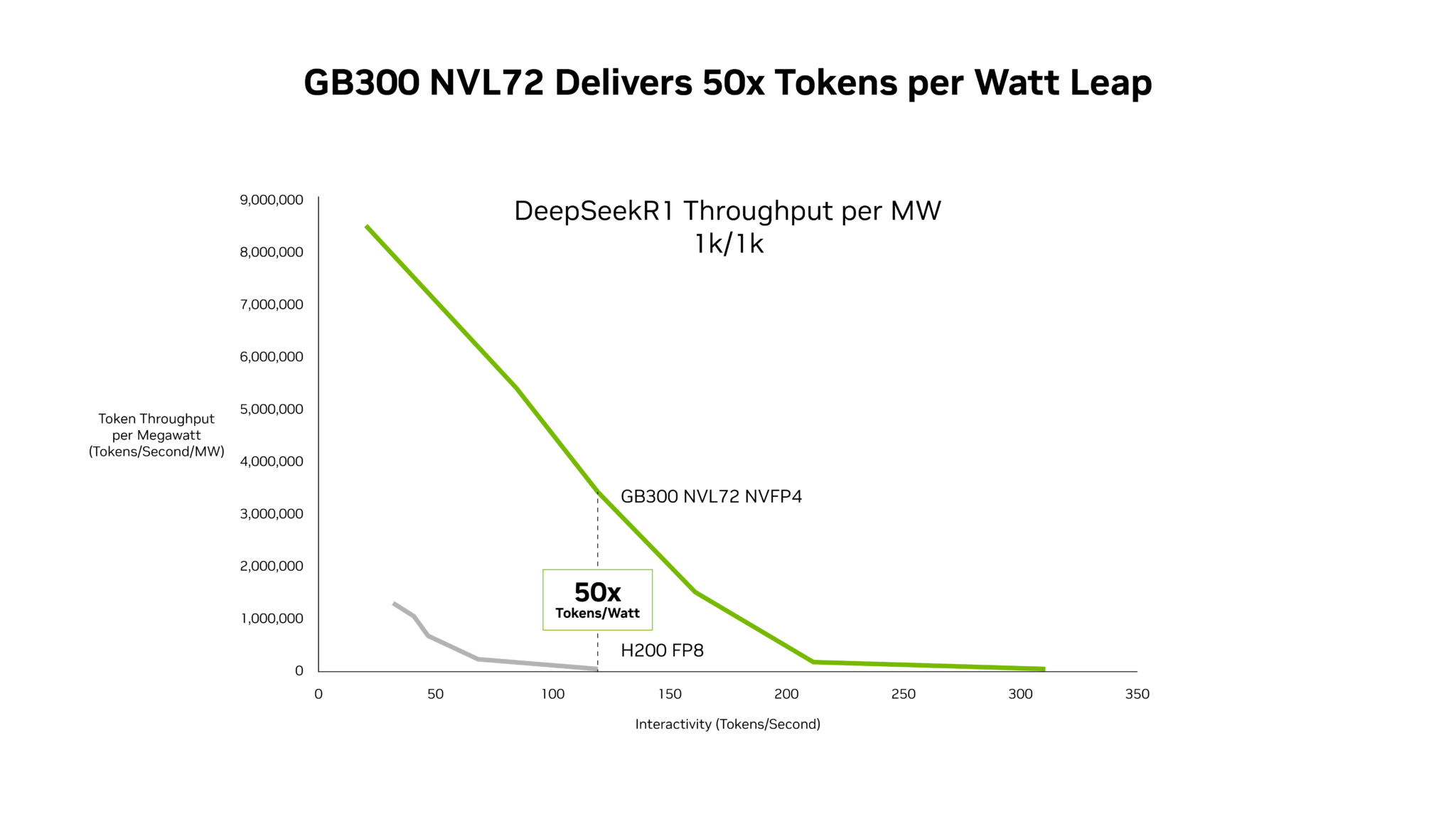
Why: Agents don't send one prompt — they run long chains of model calls and tool executions, so a serving system's real job is sustaining many such runs at once. AgentPerf measures exactly that: concurrent agents held above a speed limit, normalized by power.
vs prior: A single-shot completion benchmark sends one prompt and reports tokens per second — and misses the bursty, stateful, KV-cache-heavy load a real agent creates. Trajectory replay reproduces that load, so the score reflects real production agent load, not a sprint time.
Think of it as
An EPA mileage test that replays a real drive cycle, not a top-speed sprint.