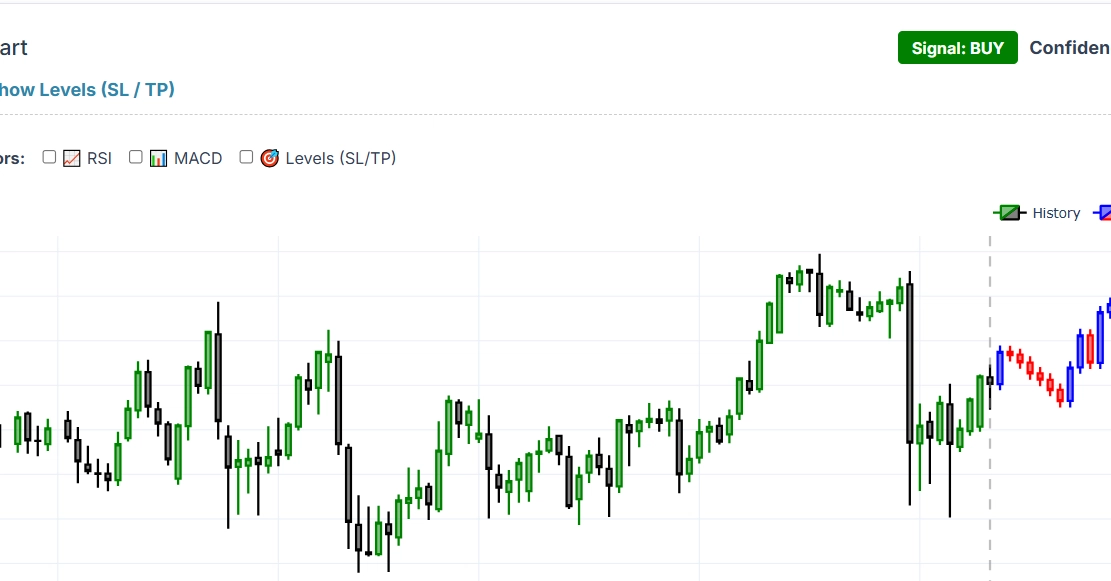
Most retail algorithmic trading bots rely heavily on legacy technical analysis indicators—think RSI, MACD, or Bollinger Bands. While these indicators are easy to calculate, they suffer from a fatal flaw: they are lagging metrics derived entirely from historical price adjustments. In high-frequency, institutional environments, relying on simple moving averages is like trying to drive a car while looking exclusively through the rearview mirror.
To build a statistical edge, modern quantitative architectures leverage predictive Machine Learning models (built with Scikit-Learn, PyTorch, or ONNX runtimes) that ingest the micro-structural state of live order books to predict near-term price direction.
However, moving a machine learning model out of a Jupyter Notebook and wiring it up to a real-time production stream introduces severe backend challenges. If your data pipeline introduces even a few milliseconds of lag during feature transformation or model inference, your predictions become stale, and your trades will execute behind the market.
In this first article of our third series on the VecTrade.io ecosystem, we will dive into pipeline engineering for real-time inference. We will look at how to build non-blocking feature generators, maintain low-latency inference loops, and convert model probabilities into risk-managed execution payloads.