Originally published at llmkube.com/blog/making-self-hosted-llm-agents-trustworthy. Cross-posted here for the dev.to audience.
Running a single local LLM node is a solved problem. You write an InferenceService, the operator schedules it, llama.cpp or MLX serves it, and you get an OpenAI-compatible endpoint. We have been doing that for months.
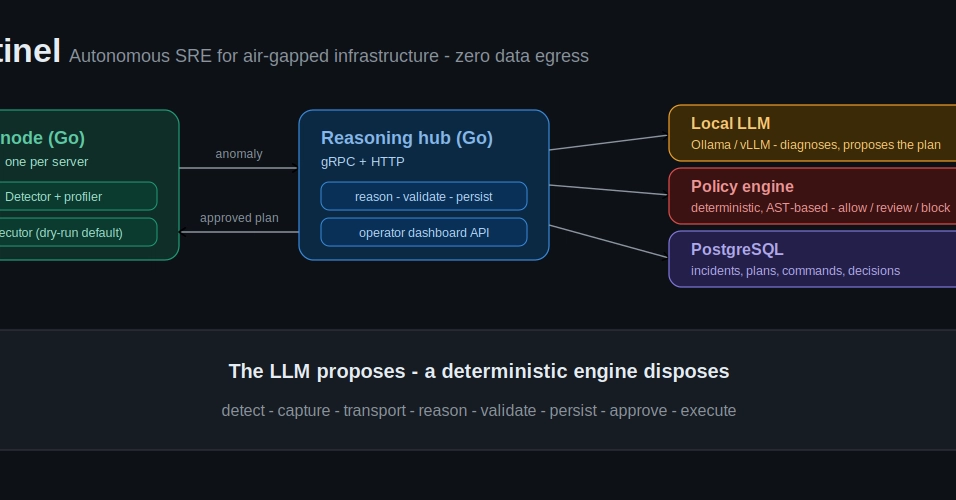
Running a fleet of them is where it stops being easy. My fleet is heterogeneous on purpose: CUDA pods in the cluster, and Apple Silicon Macs sitting off-cluster on the homelab network, each one running two separate agents (one for inference, one for the agentic coding harness). The day I shipped 0.8.4 to that fleet, I learned exactly how it does not scale.
I updated each Mac by hand. The control plane had no idea what version any agent was running. And the launchd reload I used to restart an agent was a silent no-op on an already-loaded service, so the old binary kept running while I believed I had updated it. I found that out by hand-inspecting a process tree. Three machines made it annoying. Thirty would make it impossible, and the whole pitch for sovereign, on-prem AI is that you run a lot more than three.
So the last stretch of work on LLMKube was not about a faster runtime or a bigger model. It was about making the fleet trustworthy: able to update itself safely, and unable to lie to the control plane about its own state. Here is what that took.